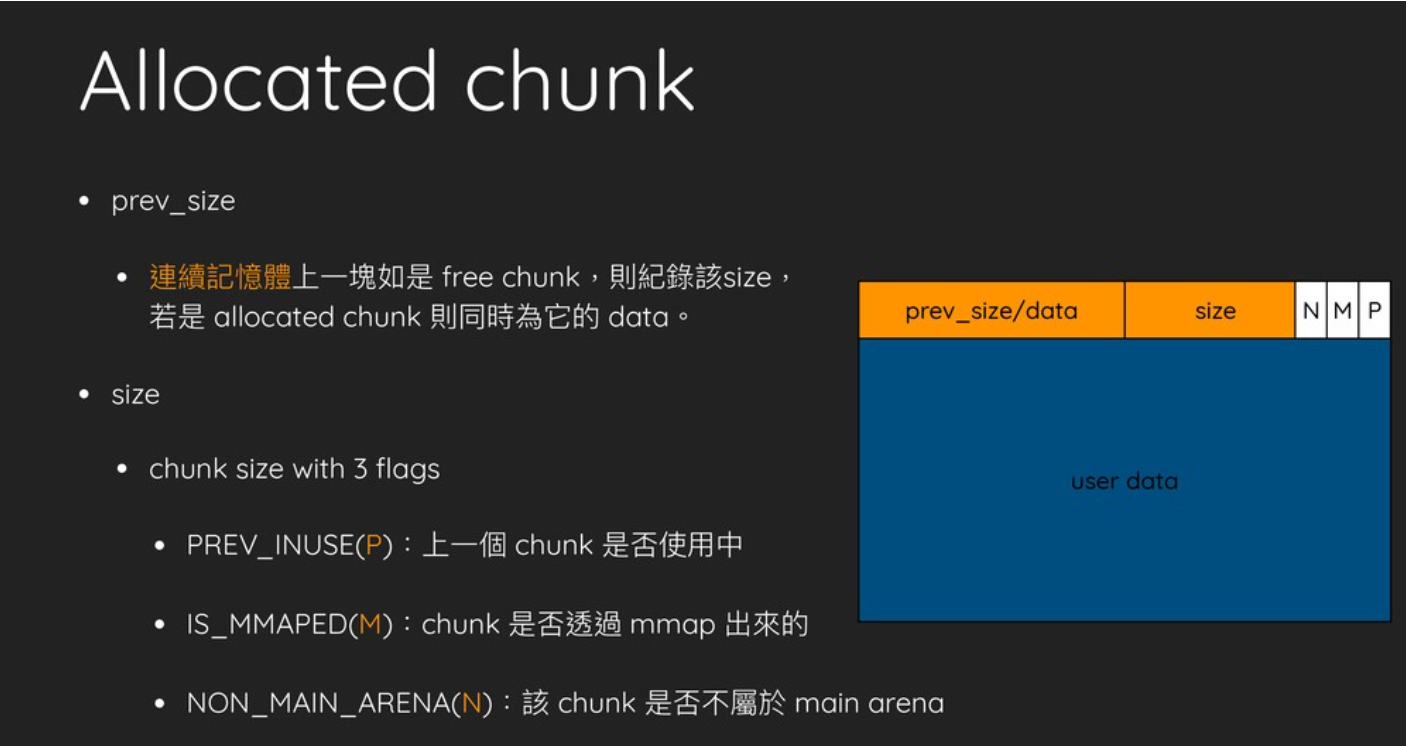
Lab3: Time-sharing Multi-tasking
In lab2, we implemented a Batch-Processing OS, allowing users to submit a bunch of programs at once then just wait for the result(s). Besides, we have made some basic security checks to prevent memory fault(or attack) in user’s programs influencing the other ones or OS. Despite the large labor-saving, it is still a far cry from a modern OS.
Think about how the OS behaves nowadays: Multi-tasking(you feel like doing many works at the same time), Real-time interaction(whenever click or press a key you get responses instantly), Memory Management, I/O Devices Management, and Networking utilities. It is those features, supported by complicated underlay mechanisms, that let us operate computers in a satisfying and efficient way. And in this lab, we are going to address the Multi-tasking problem, which takes an essential step towards our modern OS target.
The basic idea of multi-tasking on a single CPU is very simple: we run each task for a small piece of time, then switch to the next task and repeat this procedure. If we switch fast enough then it looks like we are running many programs at the same time.
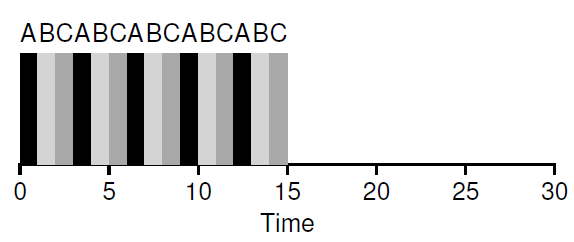
The cruxes:
- How do we allocate memory of the programs? We need to preserve the task context (registers, stack, etc) in memory so that when we switch back and everything goes fine as before.
- How to switch between tasks? The OS code cannot run when the user’s programs occupy the CPU, so we need to seize this power from the user’s programs, without destruction to them.
- How do we schedule those tasks? What is the proper time interval to perform task switching? How do decide which one should run next?
In the following parts, we will discuss these problems, one by one.