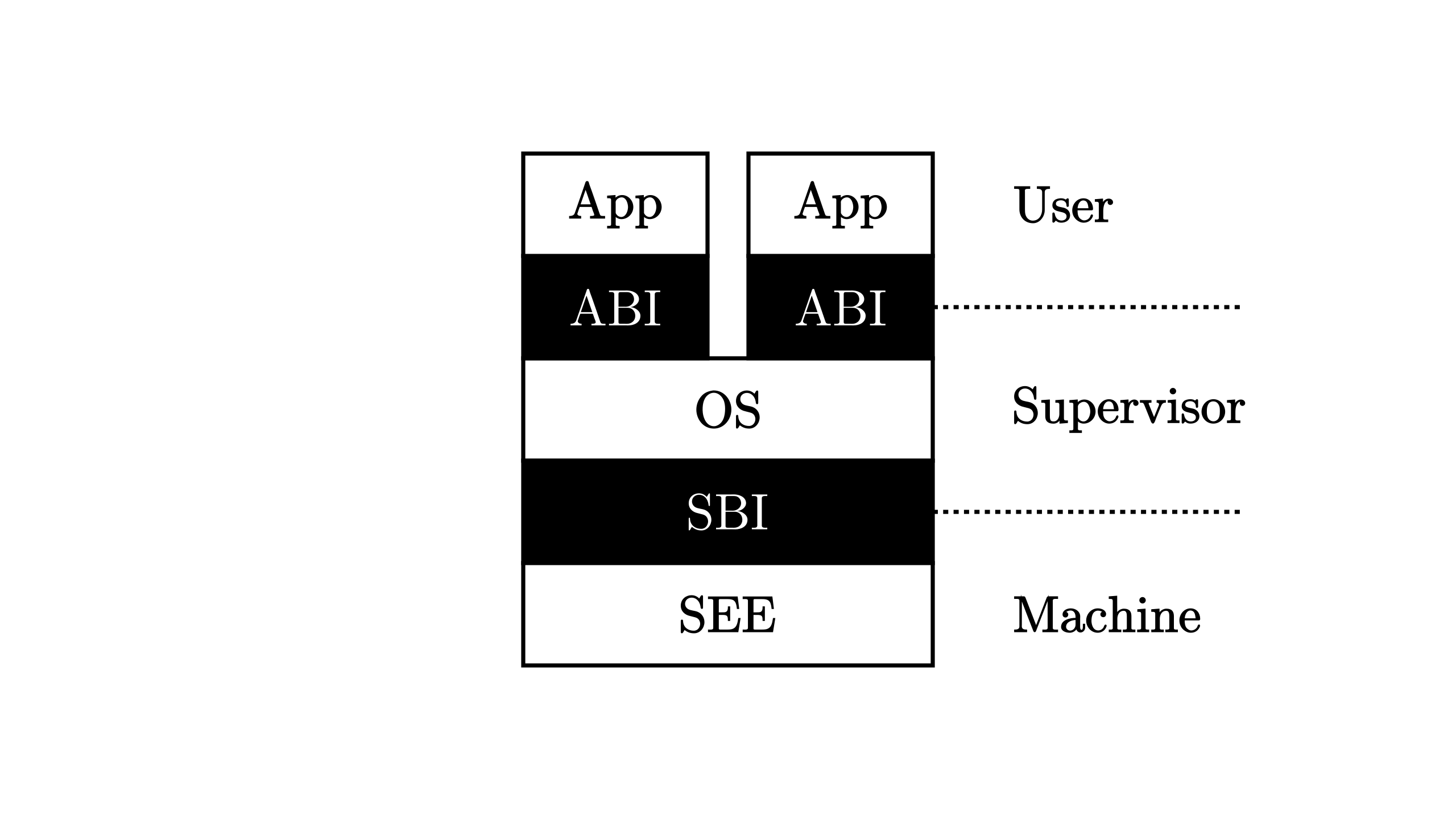
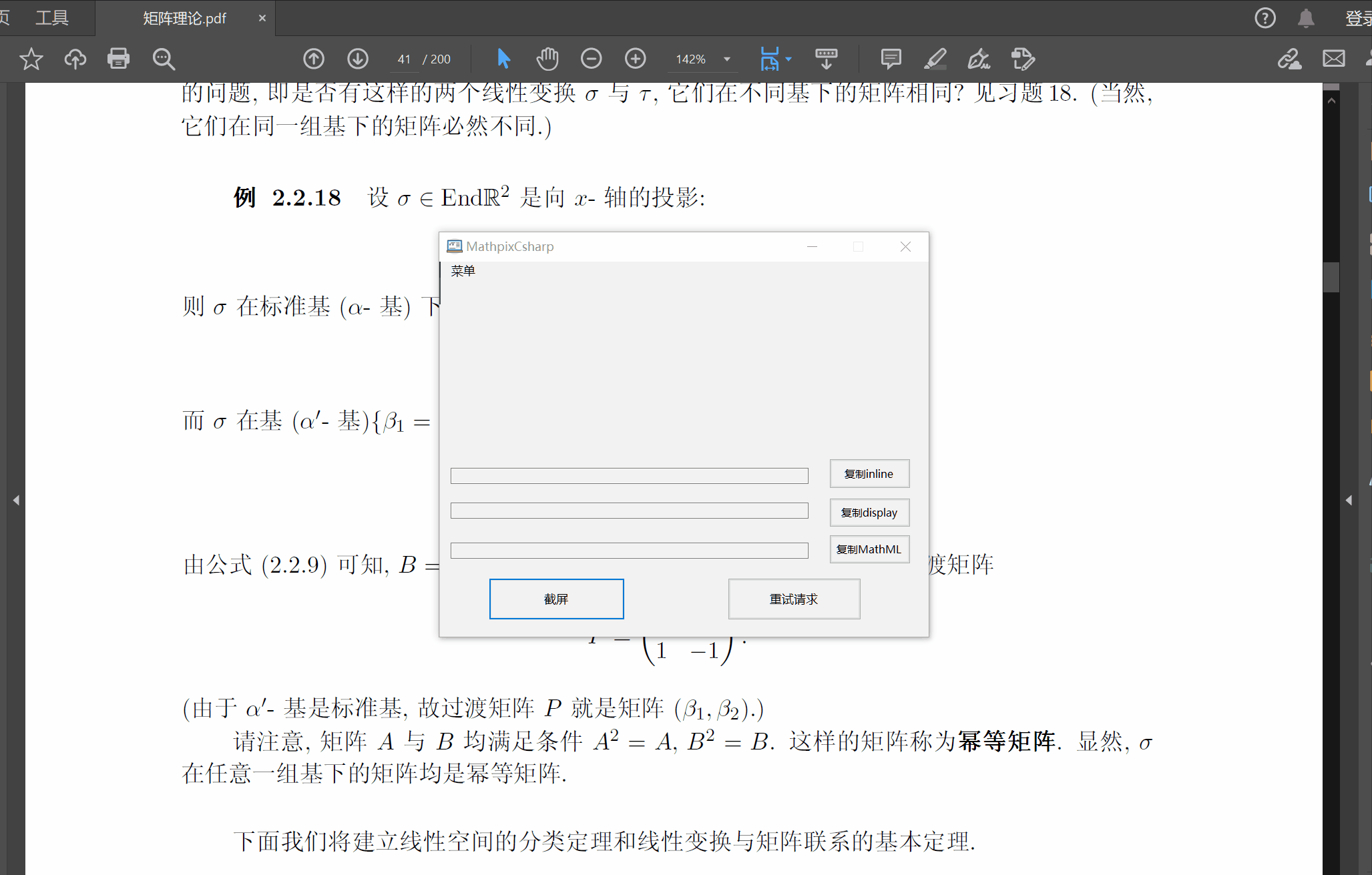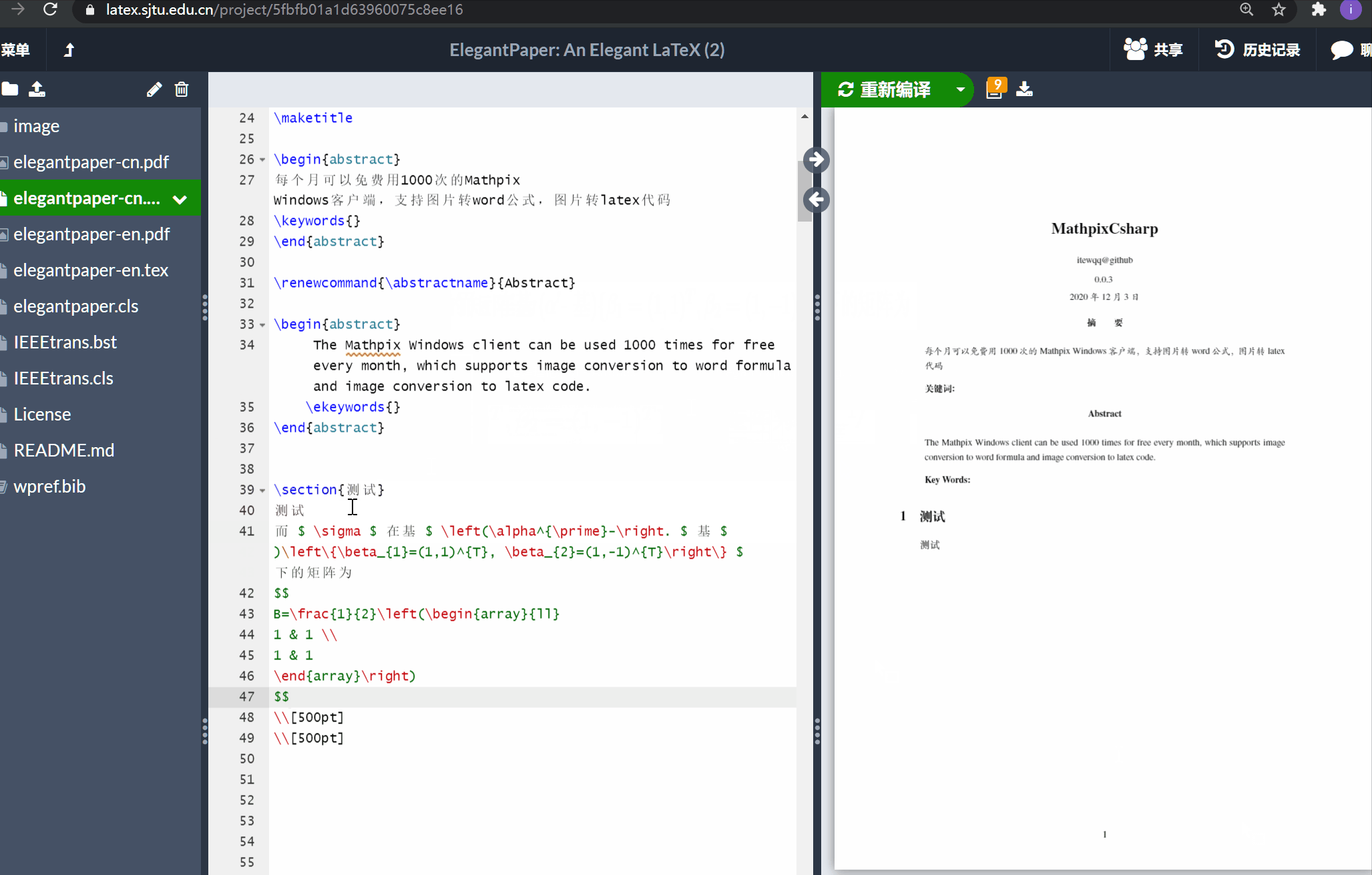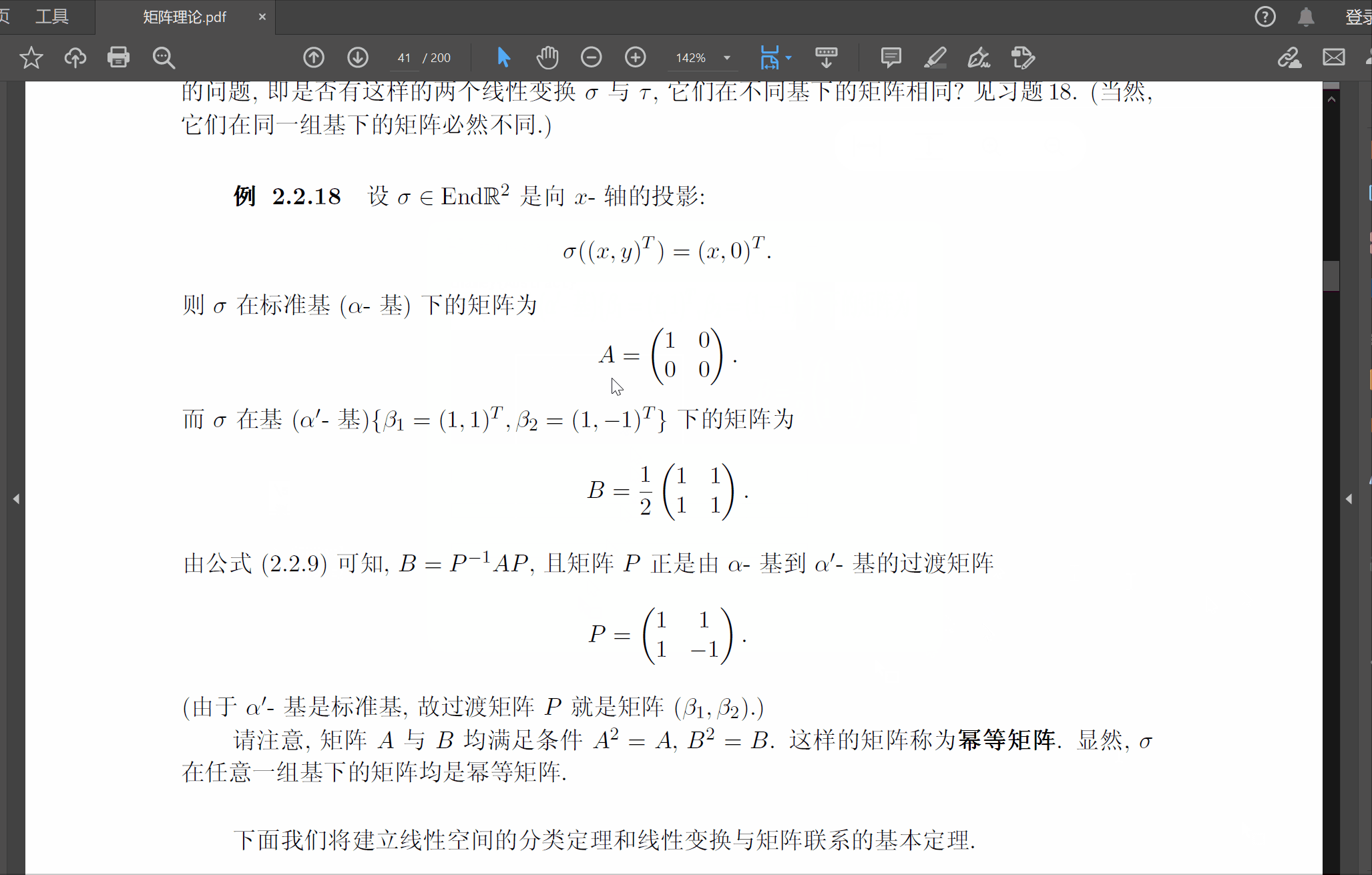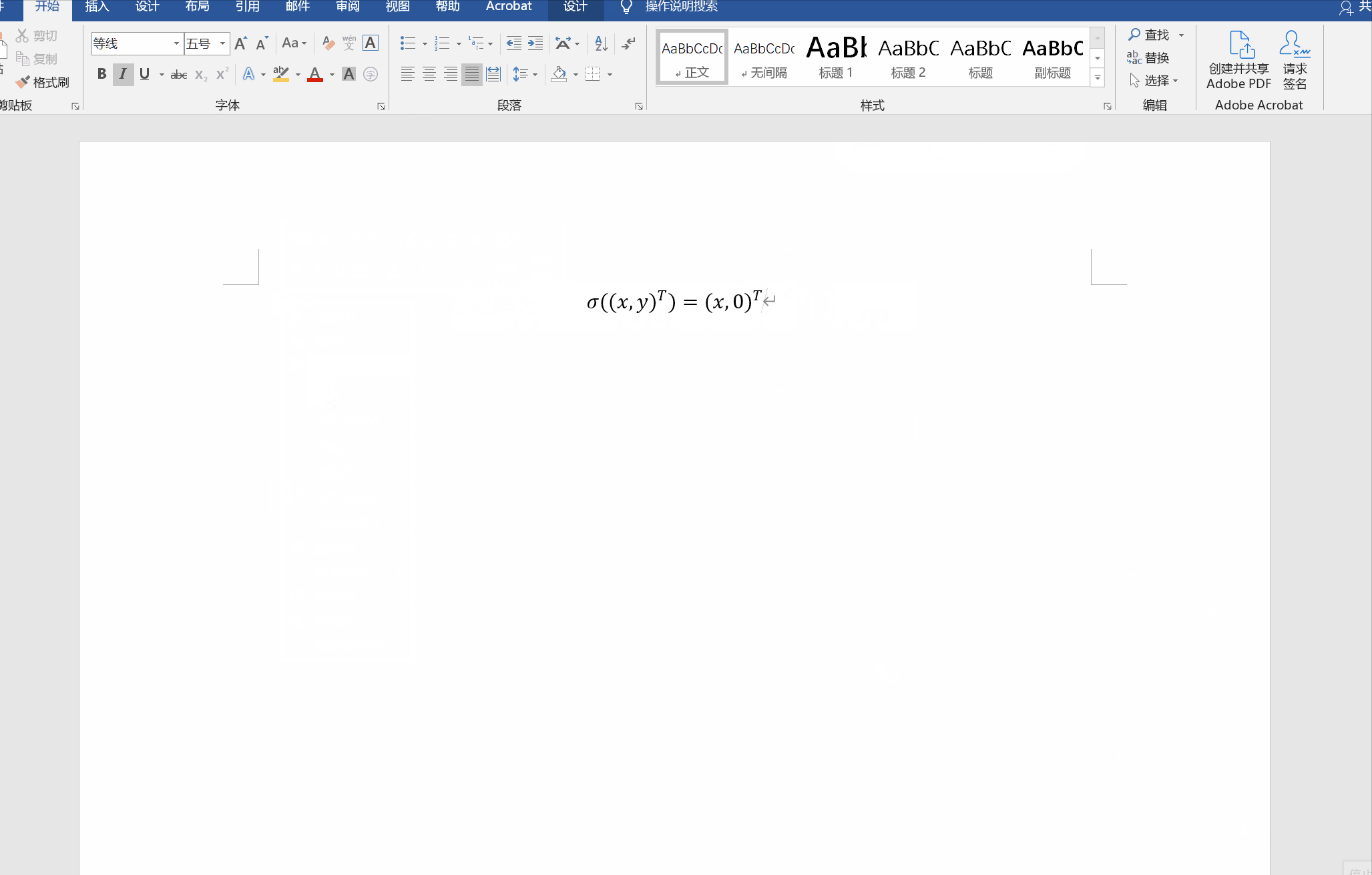
Lab4: Address Space
Address Space is a significant mechanism in modern operating system. By adding an abstract layer between code and physical memory, it frees the developers from the painful memory arrangement work, helping them focus more on their code other than the hardware stuff.
The following figure gives an overview of how Address Space works:
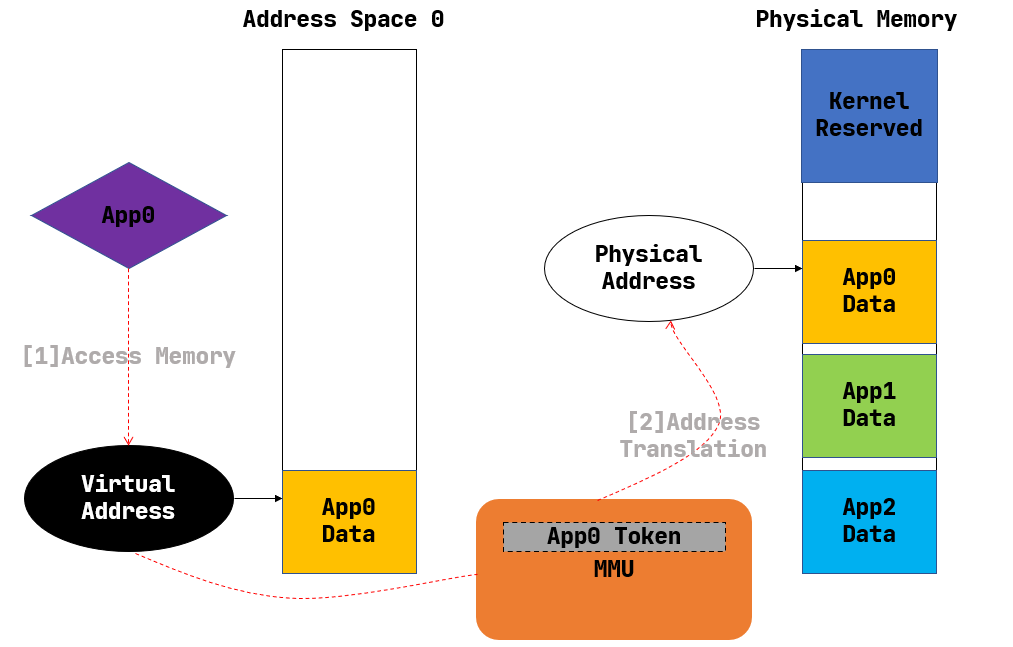
Having Address Space enabled, the codes can only see the Virtual Address. If a process wants to access any address virt_addr, it will be first translated to Physical Address by CPU’s MMU module according to the process’s page table.
0x00 Hardware supports for Multilevel Paging in RISCV
The MMU is disabled by default, thus previously any program are able to access any physical memory. We can enbale the MMU by setting a register named satp:

The above figure shows the meaning of bits in satp:
MODE controls how the MMU translate address. When MODE = 0 the MMU is disabled, and when ‘MODE’ = 8 the MMU use page table mechanism to translate the address.ASID indetifies the address space by id, since we don’t have process implemented yet we just ignore it.PPN is the physical page number of the root page table entry.
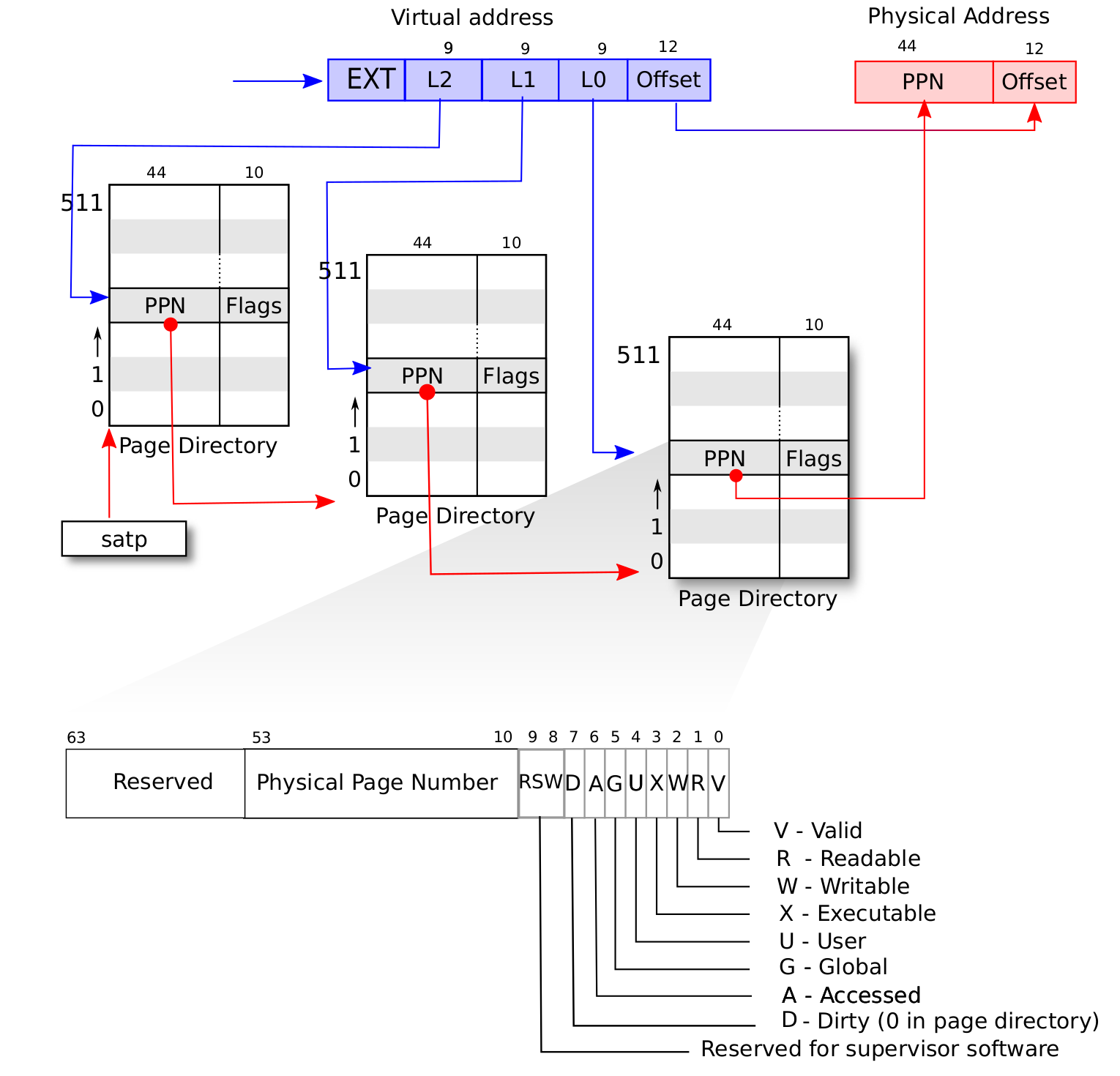
The address format under page table mechanism consists of two parts: page number and offset:

Each page table entry consists of 3 level virtual page number (vpn) and several flag bits:

With these knowledge we can easily understand how the MMU translates virtual memory address:
TLB
TLB (Translation Lookaside Buffer) works like some kinds of cache, note that we have to use sfence.vma instruction to refresh it after we change satp or any page table entry.
0x01 Address Space of Kernel and User
After satp is enabled, the memory of kernel and user applications are seperated, we need to carefully handle the interaction between different address spaces. In rCore, the designers use a Trampoline to bridge the kernel and usermode applications:
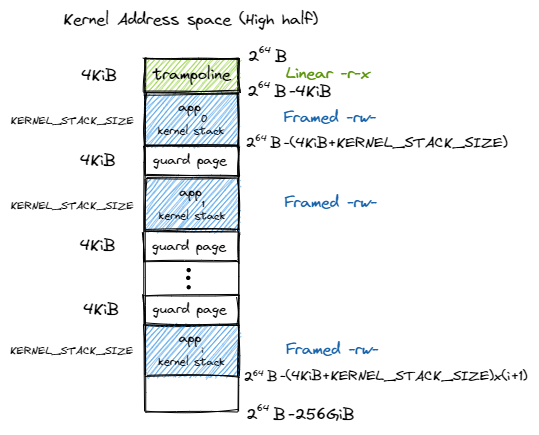
The virtual address of Trampoline is exactly same across each user spaces and the kernel space. Note that there is a guard page between kernel stacks. Those holes in the address space are settled to prevent buffer overflow damage in kernel stack.
The address space of the kernel is illustrated in the following figure:
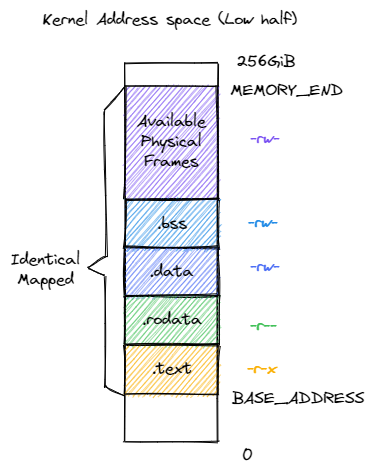
The permissions here are critical for system security: no page table can be both writable and executable. Besides, we use identical mapping here, so the kernel can read/write any user space memory in an easy way.
In user mode, the address space is quite familiar to us:
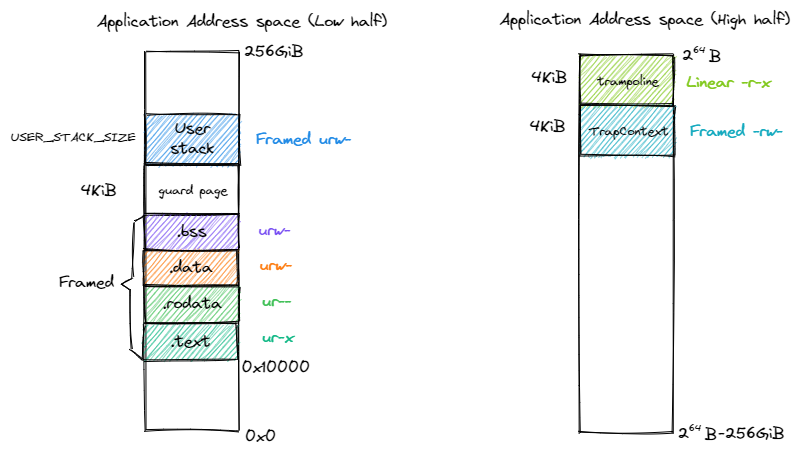
We palce the TrapContext just under the Trampoline.
0x02 Multi-tasking with Address Space
__all_traps and trap_return shoud take care of the address space switch. Note that for each task, we should set their TaskContext’s initial ra to trap_return. We don’t have the ra pushed in kernel stack for the first time to run a task so we have to handle this manually.
The syscall call stack is:
syscall: user space ecall -> __all_traps(trampoline) -> trap_handler -> do syscall -> trap_return -> __restore -> user space
The switch process is:
继续阅读“rCore-OS Lab4: Address Space”