VULNCON CTF 2021 IPS Writeup
Introduction
网络上很多<=2020年的kernel pwn writeup里的利用细节已经过时了, 像slub上的一些新的mitigations都没有被考虑进去. 今天学习了一个版本相对较新的kernel pwn, 分享一下分析和调试的过程.
题目下载: ips.tar.gz
IPS
0 solves / 500 points all available (heap) mitigations are on. perf_event_open is removed from the syscall table. get root.
Linux (none) 5.14.16 #2 SMP Mon Nov 22 19:24:06 UTC 2021 x86_64 GNU/Linux
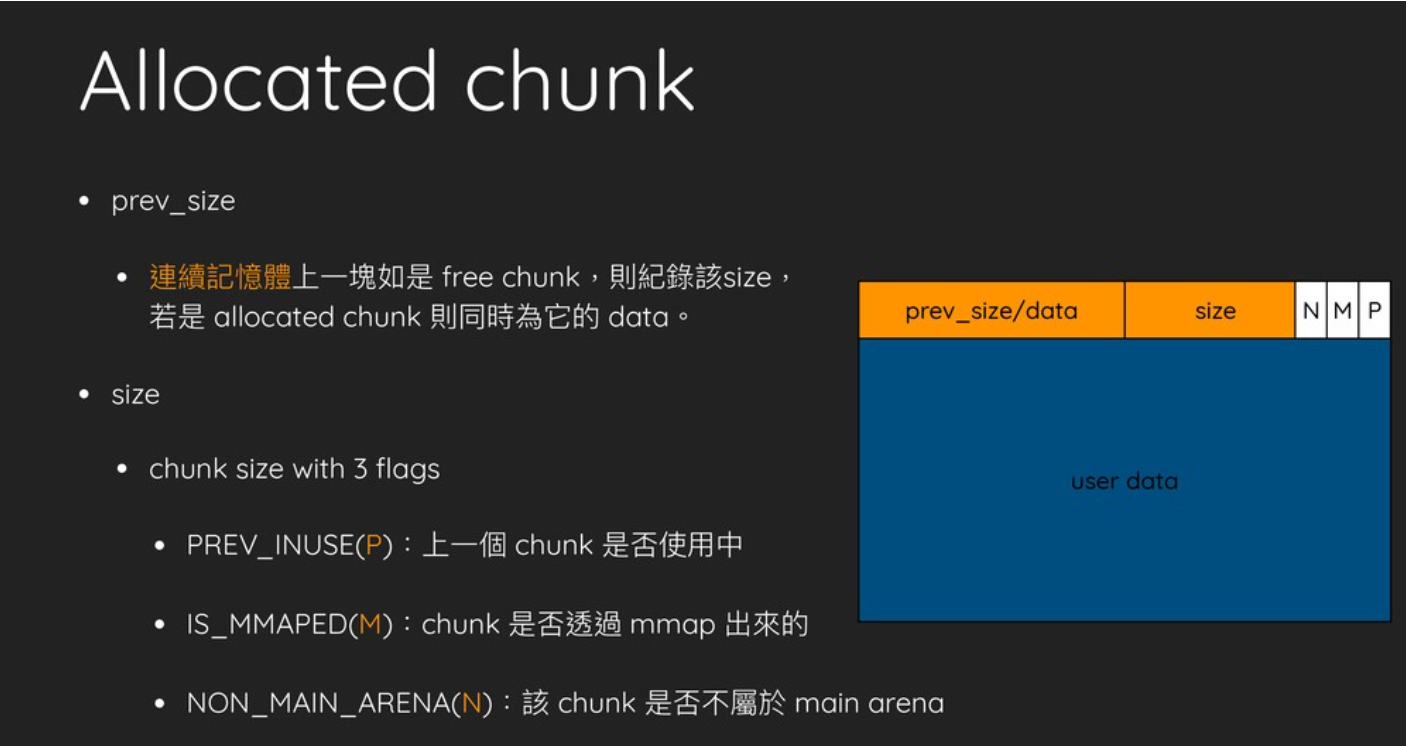
TL;DR: 实现的syscall中计算idx的逻辑有漏洞, 可以拿到一块除了前0x10外都可控的UAF. 用UAF篡改一个msg_msg结构体可进行任意长度的leak, kernel base可以直接在leak中拿到, 而根据题目中存储模式的特点可以计算出slub上的地址, 进而计算出slab random. 最终用一个UAF改掉位于chunk中间的*next拿到任意地址写, 修改modprobe path, 在用户态触发modprobe完成提权.
Analysis
Challenge setting
启动脚本:
#!/bin/bash
cd `dirname $0`
qemu-system-x86_64 \
-m 256M \
-initrd initramfs.cpio.gz \
-kernel bzImage -nographic \
-monitor /dev/null \
-s \
-append "kpti=1 +smep +smap kaslr root=/dev/ram rw console=ttyS0 oops=panic paneic=1 quiet"
开启的保护:
– ktpi: 内核页表隔离. 由于我们是用修改modprobe path的方法, 所以不需要太关注
– smep+smap: 用户态代码不可执行+用户态数据不可访问, 但是没有给qemu传-cpu参数, 所以这两个参数其实是无效的, 因此也就有了ret2user的非预期解法(见下文)
– kaslr: 内核地址随机化, 常规的防护选项, 意味着我们需要leak
解包initramfs.cpio.gz, 查看系统init命令:
继续阅读“VULNCON CTF 2021 IPS Writeup”