SUSCTF 2022 tttree writeup
前言
SUSCTF 2022 的 tttree 这道题目使用了2021 KCTF 春季赛一位师傅提出的混淆思路, 但是网上现有的公开WP(包括官方的)和混淆器的原作者都没有很好地讲清楚应该怎么去混淆. 比赛期间时间比较紧张, 很多人也来不及理清思路, 一些师傅甚至直接手撕汇编解题(orz). 综合了多位师傅的解题思路之后, 在这里总结出一份相对比较完善的去混淆思路(完整代码见文末), 希望能对读者有所帮助, 如有更好的思路, 欢迎与我交流.
0x00 初步分析
给了一个x64的Windows命令行程序:
tttree2.exe: PE32+ executable (console) x86-64, for MS Windows
直接运行, 提示输入flag:, 随便输入之后返回error!.
IDA加载, 找到start函数, 发现是一个很短的汇编函数:

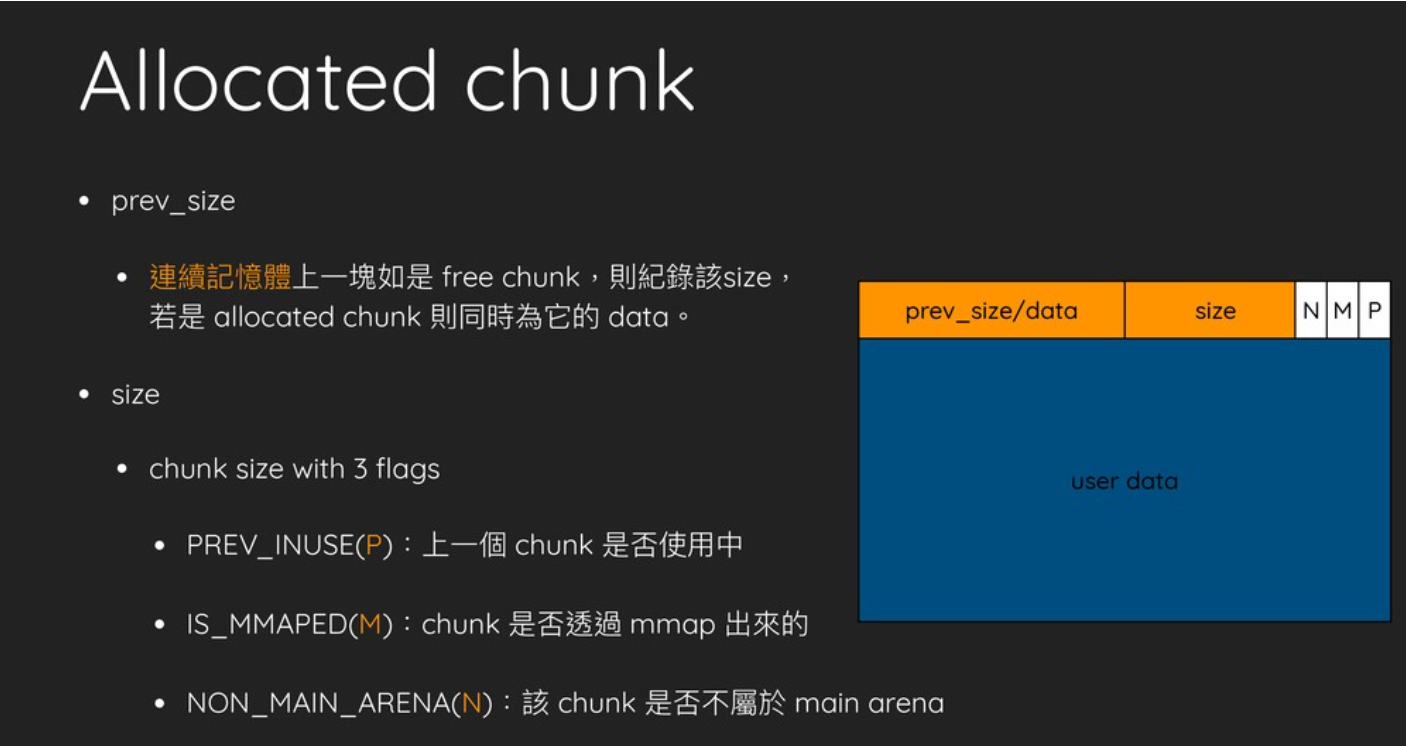
进一步发现, 几乎整个代码段都是相似的模式. 根据计算地址后是否直接retn可以将混淆模式分为两种, 第一种模式如下:
... ; 原来的汇编代码
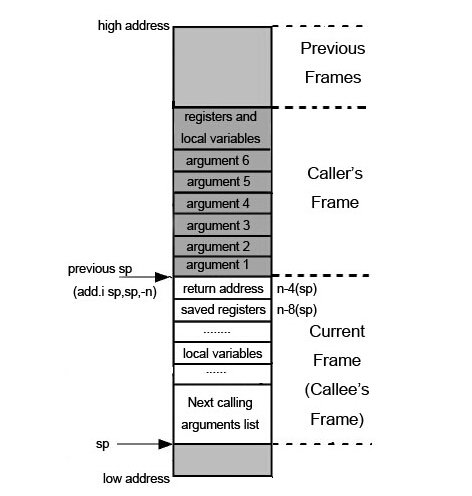
push rax
push rax
pushfq
call $+5
pop rax
add/xor rax, some_imm
mov [rsp+40h+var_30], rax
popfq
pop rax
retn
不难发现, 该段汇编代码的作用就是将call $+5的下一条指令的地址add或者xor上某个立即数, 再通过retn跳转到计算出来的新地址, 因此这种模式可以看作是一种jmp, 其通过将原来的线性汇编代码分割成多个小块, 并且随机打乱了顺序来进行混淆.
第二种模式如下:
push rdx
push rbx
pop rbx
pop rdx
push rax
push rax
pushfq
call $+5
pop rax
add rax, 4A8Ch
mov [rsp+10h], rax
popfq
pop rax
push rax
push rax
pushfq
call $+5
pop rax
add rax, 0FFFFFFFFFFFFCBEFh
mov [rsp+10h], rax
popfq
pop rax
retn
这里可以看作是两次JMP模式的组合. 区别在于, 第一次JMP模式中, 计算完跳转地址后没有立即用retn跳转, 而是又重新开始了新的一次JMP模式. 仔细一想就会发现这个模式等价于做了一次call, 其中第一次放到返回地址里的是call所在的上下文中的下一条指令, 而第二次放进去的是call所调用的函数的地址.
此外还有一些比较简单的无效指令混淆, 目的应该是增加动态调试的难度:
push rax
pop rax
push rbx
pop rbx
push rcx
push rdx
pop rdx
pop rcx
有了以上的分析基础, 就可以着手一步步来去除各种混淆了.
0x01 控制流重建
继续阅读“SUSCTF 2022 tttree writeup”