
绿色线程: 原理与实现
引言: 绿色线程(Green threads)即在用户态实现的线程, 是相对于操作系统线程(Native threads)提出的概念. 绿色线程完全由编程语言运行时环境或VM进行调度管理, 实现的是合作式的”伪”并发. 在Java 1.1中, 绿色线程是JVM中唯一的线程模型, 当时的人们普遍认为绿色线程避免了频繁的内核态-用户态切换, 在一些特定场景下可以达到更好的性能. 然而, 随着操作系统和编程语言的发展, 绿色线程由于种种原因逐渐被抛弃. 直到近年来, Go语言中goroutine的广泛使用, 用户态线程管理这一技术才重新吸引了人们的目光.
Why Threads in User Space
在分析实现原理前, 我们首先来思考一下, 既然操作系统底层已经提供了的完整的线程支持, 为什么还需要用户态线程? 前面我们提到了Go近年来迅猛发展, 而这里的答案也正与goroutine擅长处理的场景有关: 高并发.
对于并发场景, 常见的处理方式有以下几种:
- 多进程, 例如Apach的Prefork模式
- 多线程+锁, Java开发中最常用的模式
- 异步回调+事件驱动, 例如node.js
- 用户态线程/协程/纤程/绿色线程, 例如goroutine
其中, 进程消耗系统资源相对较大, 因此多进程并不适合高并发场景; 多线程避免了进程的堆, 地址空间等资源的重复分配, 相比于多进程, 大大降低了多任务并行调度的开销; 回调+事件轮询的处理模型采用了不同的思路, 通过非阻塞的方式保持CPU的持续运转; 用户态线程则是将线程的调度逻辑从内核态转移到了用户态, 相较于多线程进一步地减少了调度的开销, 实现了更细粒度的控制.
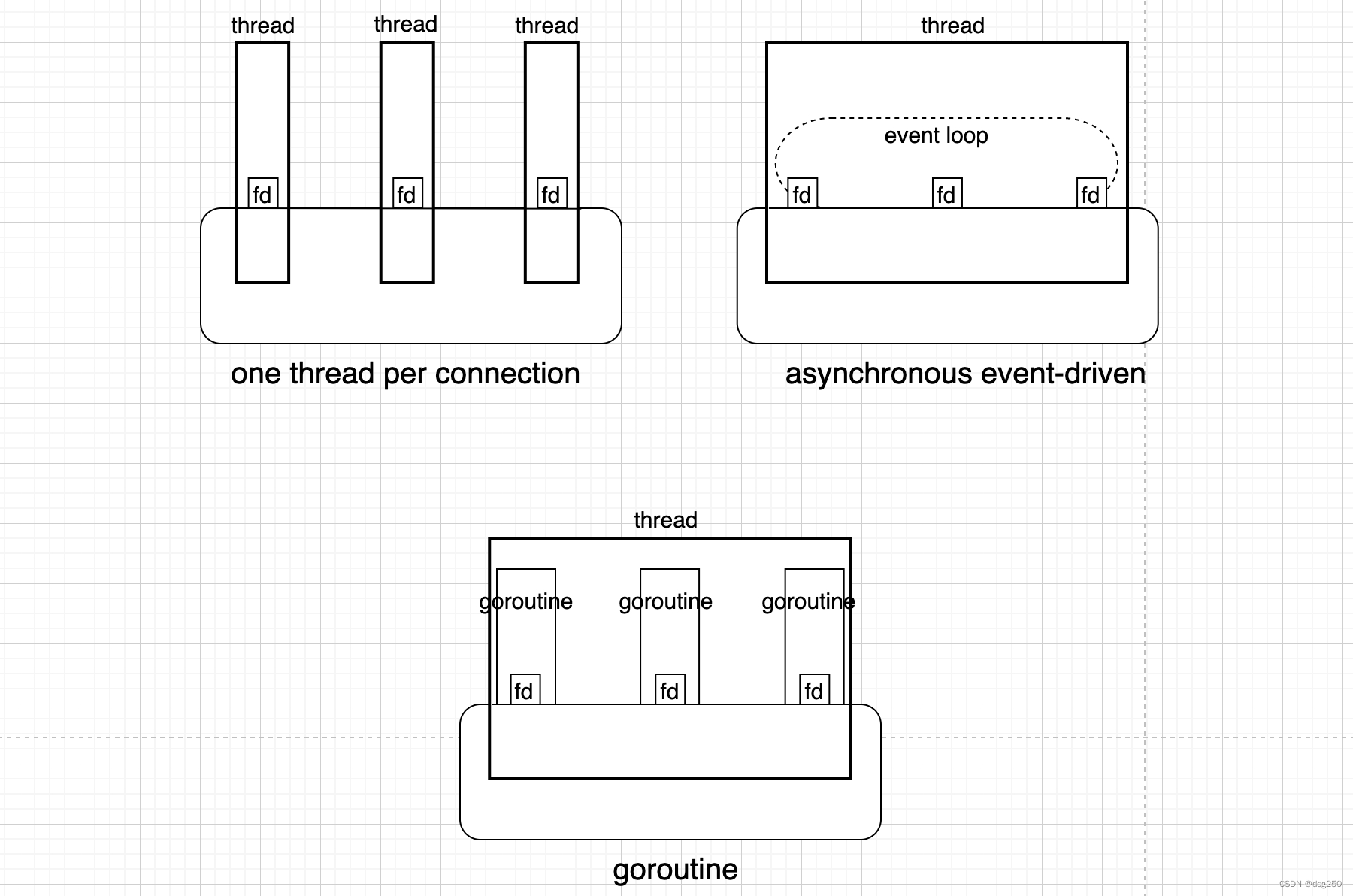
用户态线程的优势主要在于:
- 调度代价小: 用户态线程避免了特权级的转换, 而且仅使用部分寄存器即可完成上下文切换(见下文实现).
- 内存占用少: 内核线程的栈空间通常为1-2MB, 用户态线程(如goroutine)栈空间最小可以到2KB, 一个golang程序可以轻松支持10万级别的goroutine运行, 作为对比, 1000个系统线程已经需要至少1-2GB的内存了.
- 解决回调地狱: 用户态线程可以简化异步回调的代码, 提升开发人员编码的简洁性和可读性.
实现原理
线程结构体
为了实现绿色线程, 我们首先需要确定描述一个线程需要哪些信息. 根据线程的定义不难发现, 描述线程的结构体应该包括:
- 线程ID
- 运行状态
- PC
- 通用寄存器
- 栈
在x86_64架构下, 上述线程描述可以用以下代码来表示:
struct Thread {
_id: usize,
stack: Vec<u8>,
ctx: ThreadContext,
state: State,
}
struct ThreadContext {
rsp: u64,
r15: u64,
r14: u64,
r13: u64,
r12: u64,
rbx: u64,
rbp: u64,
}
enum State {
Available,
Running,
Ready,
}
其中, 绿色线程的栈我们使用一个Vec来存储, 具体的大小在实例化时指定. 对于线程状态state, 此处为了简单起见仅使用3种状态:
- Available: 线程空闲,可被分配一个任务去执行
- Running: 线程正在执行
- Ready: 线程已准备好,可恢复执行
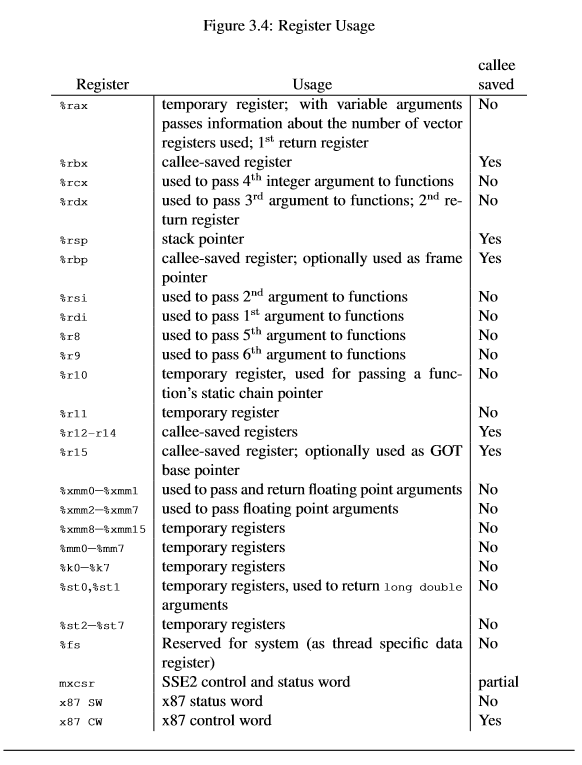
注意在程序上下文ThreadContext中, 我们只存储了部分寄存器, 也没有存储rip. 这样做的原因是, 我们后续的线程切换是通过显式函数调用来协作式地进行的, 而在x86架构的ABI中, 进行函数调用时有一些寄存器会被自动保存到栈上, 我们只需要保存ABI中callee saved的寄存器就可以了:
绿色线程运行时设计
简单起见, 我们将绿色线程的运行时定义如下结构体:
pub struct Runtime {
threads: Vec<Thread>, // 所有的绿色线程
current: usize, // 当前的绿色线程ID
}
为了能实现不同线程间的切换, 需要处理线程生命周期中的3个部分:
- 启动: 如何从主线程(或者其他线程)转到一个新的线程开始执行
- 切换: 如何从一个线程切换到另一个线程开始执行
- 退出: 当一个线程结束时, 应该如何处理
这里的设计思路和操作系统中的线程相似: 我们先实现切换功能, 再基于切换来实现启动和退出.
假设有2个已经成功启动了的绿色线程Thread1与Thread2, 正在运行的是线程1, 现在需要切换到线程2.
根据前面的分析, 我们需要将正在运行中的线程1的Thread结构体中的程序上下文替换为Thread 2的. 由于涉及到了寄存器的切换, 我们需要使用汇编代码来实现:
#[naked]
#[no_mangle]
unsafe extern "C" fn switch(old: *mut ThreadContext, new: *const ThreadContext) {
asm!(
"mov [rdi + 0x00], rsp",
"mov [rdi + 0x08], r15",
"mov [rdi + 0x10], r14",
"mov [rdi + 0x18], r13",
"mov [rdi + 0x20], r12",
"mov [rdi + 0x28], rbx",
"mov [rdi + 0x30], rbp",
"mov rsp, [rsi + 0x00]",
"mov r15, [rsi + 0x08]",
"mov r14, [rsi + 0x10]",
"mov r13, [rsi + 0x18]",
"mov r12, [rsi + 0x20]",
"mov rbx, [rsi + 0x28]",
"mov rbp, [rsi + 0x30]",
"ret",
options(noreturn)
);
}
基于switch函数, 很容易设计出管理线程切换的代码:
impl Runtime {
#[inline(never)]
pub fn t_yield(&mut self) -> bool {
let mut new_pos = self.current;
while self.threads[new_pos].state != State::Ready {
new_pos += 1;
if new_pos == self.threads.len() {
new_pos = 0;
}
// if no Ready thread, exit the runtime
if new_pos == self.current {
return false;
}
}
if self.threads[self.current].state != State::Available {
self.threads[self.current].state = State::Ready;
}
self.threads[new_pos].state = State::Running;
let old_pos = self.current;
self.current = new_pos;
unsafe {
let old: *mut ThreadContext = &mut self.threads[old_pos].ctx;
let new: *mut ThreadContext = &mut self.threads[new_pos].ctx;
switch(old, new);
}
true
}
}
注意switch中执行ret指令时, 当前程序的栈已经被换过了, 因此会直接跳到新栈上保存的返回地址, 而不是返回之前调用它的t_yield(当然它可能返回到另外一个线程的t_yiled). 这个特性可以帮助我们解决线程启动的问题: 我们只要在初始化线程结构体的时候向栈上返回地址的位置填入线程处理函数的地址, 然后从主线程yield过去就可以了.
关于线程的退出问题, 也可以用同样的方法: 在上述返回地址填充的基础上, 再填充一个返回地址, 指向处理程序退出的函数(其实就是ROP). 此时线程的初始化栈布局为:
| whatever | rsp+32 (rbp)
| padding | rsp+24
| exit handler | rsp+16
| ret | rsp+8
| thread function | rsp
其中rsp+8的ret和rsp+24的padding是为了满足x86_64的ABI关于rbp/rsp需0x10对齐的要求. 根据栈布局不难写出spawn线程的代码:
impl Runtime {
pub fn spawn(&mut self, f: fn()) {
let available = self
.threads
.iter_mut()
.find(|t| t.state == State::Available)
.expect("No available threads");
let stack_size = available.stack.len();
unsafe {
let rbp = available.stack.as_mut_ptr().offset(stack_size as isize);
let rbp = (rbp as usize & !15) as *mut u8;
std::ptr::write(rbp.offset(-16) as *mut u64, guard as u64);
std::ptr::write(rbp.offset(-24) as *mut u64, skip as u64);
std::ptr::write(rbp.offset(-32) as *mut u64, f as u64);
available.ctx.rsp = rbp.offset(-32) as u64;
}
available.state = State::Ready;
}
}
处理线程退出的函数t_return代码如下, 因为我们这里的绿色线程实现比较简单, 暂且不需要考虑资源回收问题, 仅仅更新线程状态为Available后t_yield到其他线程即可.
impl Runtime {
pub fn t_return(&mut self) {
if self.current != 0 {
self.threads[self.current].state = State::Available;
self.t_yield();
}
}
}
实现细节
由于rust本身对线程安全进行了严格的限制, 我们需要额外使用一些unsafe块来包装一个Runtime的全局可变引用, 具体实现细节见下方完整代码:
#![feature(naked_functions)]
use core::arch::asm;
const STACK_SIZE: usize = 2 * 1024 * 1024; // 2MB Stack
const MAX_THREAD_NUM: usize = 4;
static mut RUNTIME: usize = 0;
#[derive(Debug, Default)]
#[repr(C)]
struct ThreadContext {
rsp: u64,
r15: u64,
r14: u64,
r13: u64,
r12: u64,
rbx: u64,
rbp: u64,
}
#[derive(PartialEq, Eq, Debug)]
enum State {
Available,
Running,
Ready,
}
struct Thread {
_id: usize,
stack: Vec<u8>,
ctx: ThreadContext,
state: State,
}
impl Thread {
pub fn new(id: usize) -> Self {
Self {
_id: id,
stack: vec![0_u8; STACK_SIZE],
ctx: ThreadContext::default(),
state: State::Available,
}
}
}
pub struct Runtime {
threads: Vec<Thread>,
current: usize,
}
impl Runtime {
pub fn new() -> Self {
let base_thread = Thread {
_id: 0,
stack: vec![0_u8; STACK_SIZE],
ctx: ThreadContext::default(),
state: State::Running,
};
let mut threads = vec![base_thread];
let available_threads: Vec<Thread> =
(1..MAX_THREAD_NUM).map(move |i| Thread::new(i)).collect();
threads.extend(available_threads);
Self {
threads,
current: 0,
}
}
pub fn init(&mut self) {
unsafe {
let this_ptr: *mut Runtime = self;
RUNTIME = this_ptr as usize;
}
}
pub fn spawn(&mut self, f: fn()) {
let available = self
.threads
.iter_mut()
.find(|t| t.state == State::Available)
.expect("No available threads");
let stack_size = available.stack.len();
unsafe {
let rbp = available.stack.as_mut_ptr().offset(stack_size as isize);
let rbp = (rbp as usize & !15) as *mut u8;
std::ptr::write(rbp.offset(-16) as *mut u64, guard as u64);
std::ptr::write(rbp.offset(-24) as *mut u64, skip as u64);
std::ptr::write(rbp.offset(-32) as *mut u64, f as u64);
available.ctx.rsp = rbp.offset(-32) as u64;
}
available.state = State::Ready;
}
#[inline(never)]
pub fn t_yield(&mut self) -> bool {
let mut new_pos = self.current;
while self.threads[new_pos].state != State::Ready {
new_pos += 1;
if new_pos == self.threads.len() {
new_pos = 0;
}
// if no Ready thread, exit the runtime
if new_pos == self.current {
return false;
}
}
if self.threads[self.current].state != State::Available {
self.threads[self.current].state = State::Ready;
}
self.threads[new_pos].state = State::Running;
let old_pos = self.current;
self.current = new_pos;
unsafe {
let old: *mut ThreadContext = &mut self.threads[old_pos].ctx;
let new: *mut ThreadContext = &mut self.threads[new_pos].ctx;
switch(old, new);
}
true
}
// real return
pub fn t_return(&mut self) {
if self.current != 0 {
self.threads[self.current].state = State::Available;
self.t_yield();
}
}
pub fn run(&mut self) -> ! {
while self.t_yield() {}
std::process::exit(0);
}
}
fn guard() {
unsafe {
let runtime_ptr = RUNTIME as *mut Runtime;
(*runtime_ptr).t_return();
}
}
#[naked]
unsafe extern "C" fn skip() {
asm!("ret", options(noreturn))
}
pub fn yield_thread() {
unsafe {
let runtime_ptr = RUNTIME as *mut Runtime;
(*runtime_ptr).t_yield();
}
}
#[naked]
#[no_mangle]
unsafe extern "C" fn switch(old: *mut ThreadContext, new: *const ThreadContext) {
asm!(
"mov [rdi + 0x00], rsp",
"mov [rdi + 0x08], r15",
"mov [rdi + 0x10], r14",
"mov [rdi + 0x18], r13",
"mov [rdi + 0x20], r12",
"mov [rdi + 0x28], rbx",
"mov [rdi + 0x30], rbp",
"mov rsp, [rsi + 0x00]",
"mov r15, [rsi + 0x08]",
"mov r14, [rsi + 0x10]",
"mov r13, [rsi + 0x18]",
"mov r12, [rsi + 0x20]",
"mov rbx, [rsi + 0x28]",
"mov rbp, [rsi + 0x30]",
"ret",
options(noreturn)
);
}
fn main() {
let mut runtime = Runtime::new();
runtime.init();
runtime.spawn(|| {
println!("THREAD 1 STARTING");
let id = 1;
for i in 0..10 {
println!("thread: {} counter: {}", id, i);
yield_thread();
}
println!("THREAD 1 FINISHED");
});
runtime.spawn(|| {
println!("THREAD 2 STARTING");
let id = 2;
for i in 0..15 {
println!("thread: {} counter: {}", id, i);
yield_thread();
}
println!("THREAD 2 FINISHED");
});
runtime.spawn(|| {
println!("THREAD 3 STARTING");
let id = 3;
for i in 0..10 {
println!("thread: {} counter: {}", id, i);
yield_thread();
}
println!("THREAD 3 FINISHED");
});
runtime.run();
}
运行:
$ cargo run
Compiling ralgo v0.1.0 (/home/itewqq/ralgo)
Finished dev [unoptimized + debuginfo] target(s) in 0.46s
Running `target/debug/ralgo`
THREAD 1 STARTING
thread: 1 counter: 0
THREAD 2 STARTING
thread: 2 counter: 0
THREAD 3 STARTING
thread: 3 counter: 0
thread: 1 counter: 1
thread: 2 counter: 1
thread: 3 counter: 1
thread: 1 counter: 2
thread: 2 counter: 2
thread: 3 counter: 2
thread: 1 counter: 3
thread: 2 counter: 3
thread: 3 counter: 3
thread: 1 counter: 4
thread: 2 counter: 4
thread: 3 counter: 4
thread: 1 counter: 5
thread: 2 counter: 5
thread: 3 counter: 5
thread: 1 counter: 6
thread: 2 counter: 6
thread: 3 counter: 6
thread: 1 counter: 7
thread: 2 counter: 7
thread: 3 counter: 7
thread: 1 counter: 8
thread: 2 counter: 8
thread: 3 counter: 8
thread: 1 counter: 9
thread: 2 counter: 9
thread: 3 counter: 9
THREAD 1 FINISHED
thread: 2 counter: 10
THREAD 3 FINISHED
thread: 2 counter: 11
thread: 2 counter: 12
thread: 2 counter: 13
thread: 2 counter: 14
THREAD 2 FINISHED
References
本文主要参考了以下文章: