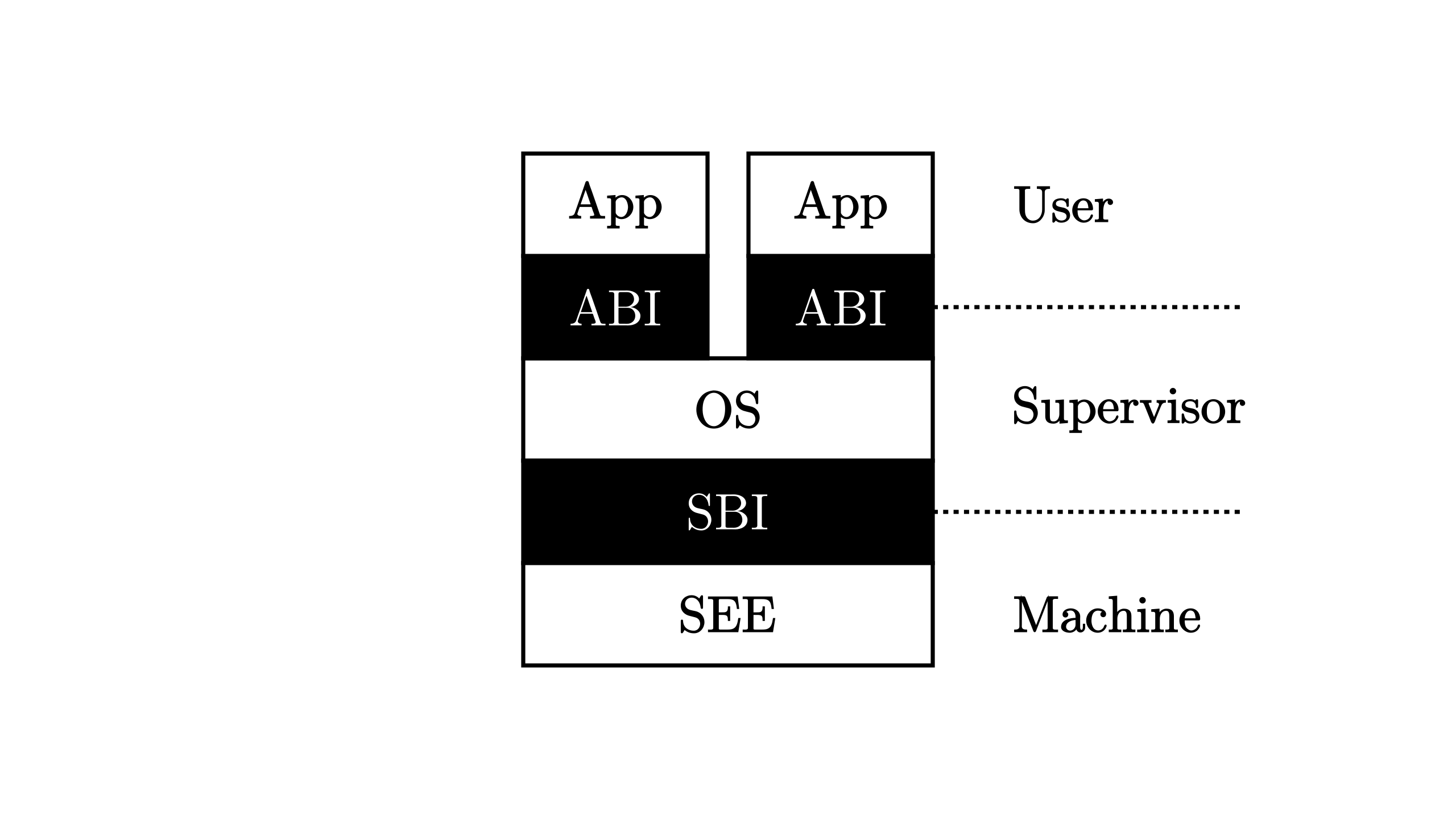
这波reverse全军覆没了属于是,最后1/7。。然后队友依然打到了rank3 orz orz
自己全场只看了两个题,最后0输出,麻了。
IDAAAAAA
这题tmd是个misc题吧
tag: 细节+脑洞
错误的分析方法:dump出来elf然后gdb调试
只给了idb,没有elf,直接打开发现是一个将输入解析为按照+号和-号分隔开的三个数字,比如输入-123+5+6,就会得到-123,5,6三个数字。然后这三个数字直接静态看的话必须满足5个约束条件:
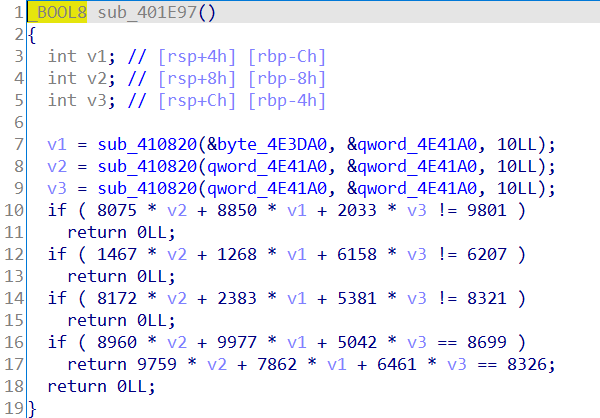
但是直接在2^32的域上求解这5个方程是求不出解的,然后大家就都懵逼了,甚至开始尝试从中选三个出来解。但是这样即使把所有的情况都解出来也是错误的
正确的分析方法:看给的idb
这个idb其实一打开可以发现有一个断点,我当时脑子里大概有一秒钟疑惑了下为啥有个断点,然后就没管他。。然后就错过了
后面我直接用IDA连gdbserver调试的时候,会发现每次执行完scanf都会直接运行结束,当时以为是IDA抽风了。。没想到是故意的,但凡多想一下这个flag也到手了
然后进入正题,这个断点右键编辑,会发现里面的condition是有idapython脚本的(脚本很长,打开这个断点的时候IDA会卡一会儿):

撸出来之后:
global jIS40A
jIS40A = [...] # 一个长度1000的list,每个item是一堆bytes
N4QKUt = 0
EpUdLx = 4728923
idaapi.add_bpt(EpUdLx)
uwGgnM = idaapi.bpt_t()
idaapi.get_bpt(EpUdLx, uwGgnM)
uwGgnM.elang = "Python"
uwGgnM.condition = "N4QKUt = {}\n".format(N4QKUt) + 'VLzxDy = idaapi.get_byte(5127584 + N4QKUt)\nVLzxDy -= ord(\'a\')\nif VLzxDy == 0:\n bYsMTa = 287\n LjzrdT = b\'lqAT7pNI3BX\'\nelif VLzxDy == 1:\n bYsMTa = 96\n LjzrdT = b\'z3Uhis74aPq\'\nelif VLzxDy == 2:\n bYsMTa = 8\n LjzrdT = b\'9tjseMGBHR5\'\nelif VLzxDy == 3:\n bYsMTa = 777\n LjzrdT = b\'FhnvgMQjexH\'\nelif VLzxDy == 4:\n bYsMTa = 496\n LjzrdT = b\'SKnZ51f9WsE\'\nelif VLzxDy == 5:\n bYsMTa = 822\n LjzrdT = b\'gDJy104BSHW\'\nelif VLzxDy == 6:\n bYsMTa = 914\n LjzrdT = b\'PbRV4rSM7fd\'\nelif VLzxDy == 7:\n bYsMTa = 550\n LjzrdT = b\'WHPnoMTsbx3\'\nelif VLzxDy == 8:\n bYsMTa = 273\n LjzrdT = b\'mLx5hvlqufG\'\nelif VLzxDy == 9:\n bYsMTa = 259\n LjzrdT = b\'QvKgNmUFTnW\'\nelif VLzxDy == 10:\n bYsMTa = 334\n LjzrdT = b\'TCrHaitRfY1\'\nelif VLzxDy == 11:\n bYsMTa = 966\n LjzrdT = b\'m26IAvjq1zC\'\nelif VLzxDy == 12:\n bYsMTa = 331\n LjzrdT = b\'dQb2ufTZwLX\'\nelif VLzxDy == 13:\n bYsMTa = 680\n LjzrdT = b\'Y6Sr7znOeHL\'\nelif VLzxDy == 14:\n bYsMTa = 374\n LjzrdT = b\'hLFj1wl5A0U\'\nelif VLzxDy == 15:\n bYsMTa = 717\n LjzrdT = b\'H6W03R7TLFe\'\nelif VLzxDy == 16:\n bYsMTa = 965\n LjzrdT = b\'fphoJwDKsTv\'\nelif VLzxDy == 17:\n bYsMTa = 952\n LjzrdT = b\'CMF1Vk7NH4O\'\nelif VLzxDy == 18:\n bYsMTa = 222\n LjzrdT = b\'43PSbAlgLqj\'\nelse:\n bYsMTa = -1\nif bYsMTa < 0:\n cpu.rsp -= 8\n cpu.rdi = 4927649\n cpu.rax = 0\n idaapi.patch_qword(cpu.rsp, 4202616)\n idaapi.del_bpt(cpu.rip)\n cpu.rip = 4263680\nelse:\n zaqhdD = 0x486195\n bYsMTa = jIS40A[bYsMTa]\n\n idaapi.patch_bytes(5117568, bYsMTa)\n idaapi.patch_bytes(5117488, LjzrdT)\n\n cpu.rsp -= 8\n idaapi.patch_qword(cpu.rsp, zaqhdD)\n cpu.rdi = 5117568\n cpu.rsi = len(bYsMTa)\n cpu.rdx = 5117488\n cpu.rcx = 11\n cpu.r8 = 5117568\n cpu.rax = 5117568\n\n idaapi.add_bpt(zaqhdD)\n jQfwUA = idaapi.bpt_t()\n idaapi.get_bpt(zaqhdD, jQfwUA)\n jQfwUA.elang = "Python"\n jQfwUA.condition = "N4QKUt = {}\\nSdjOr3 = {}\\n".format(N4QKUt, len(bYsMTa)) + \'bYsMTa = idaapi.get_bytes(cpu.rax, SdjOr3).decode()\\nzaqhdD = 4767838\\nidaapi.add_bpt(zaqhdD)\\njQfwUA = idaapi.bpt_t()\\nidaapi.get_bpt(zaqhdD, jQfwUA)\\njQfwUA.elang = "Python"\\njQfwUA.condition = "N4QKUt = {}\\\\n".format(N4QKUt+1) + bYsMTa\\nidaapi.del_bpt(zaqhdD)\\nidaapi.add_bpt(jQfwUA)\\nidaapi.del_bpt(cpu.rip)\\ncpu.rsp -= 8\\nidaapi.patch_qword(cpu.rsp, zaqhdD)\\ncpu.rip = 4447160\\n\'\n idaapi.del_bpt(zaqhdD)\n idaapi.add_bpt(jQfwUA)\n idaapi.del_bpt(cpu.rip)\n cpu.rip = 4201909\n'
idaapi.del_bpt(EpUdLx)
idaapi.add_bpt(uwGgnM)
cpu.rsp -= 8
idaapi.patch_qword(cpu.rsp, EpUdLx)
cpu.rip = 4202096
不难发现是在这个脚本里面设置了新的断点,而且在新的断点里面加入了新的condition脚本,然后移动eip到一个能执行到断点的位置,我们condition里面的字节解析出来是:
继续阅读“L3HCTF 2021 Reverse 两道题解 (IDAAAAAA double-joy)”