
SUSCTF 2022 tttree writeup
前言
SUSCTF 2022 的 tttree 这道题目使用了2021 KCTF 春季赛一位师傅提出的混淆思路, 但是网上现有的公开WP(包括官方的)和混淆器的原作者都没有很好地讲清楚应该怎么去混淆. 比赛期间时间比较紧张, 很多人也来不及理清思路, 一些师傅甚至直接手撕汇编解题(orz). 综合了多位师傅的解题思路之后, 在这里总结出一份相对比较完善的去混淆思路(完整代码见文末), 希望能对读者有所帮助, 如有更好的思路, 欢迎与我交流.
0x00 初步分析
给了一个x64的Windows命令行程序:
tttree2.exe: PE32+ executable (console) x86-64, for MS Windows
直接运行, 提示输入flag:, 随便输入之后返回error!.
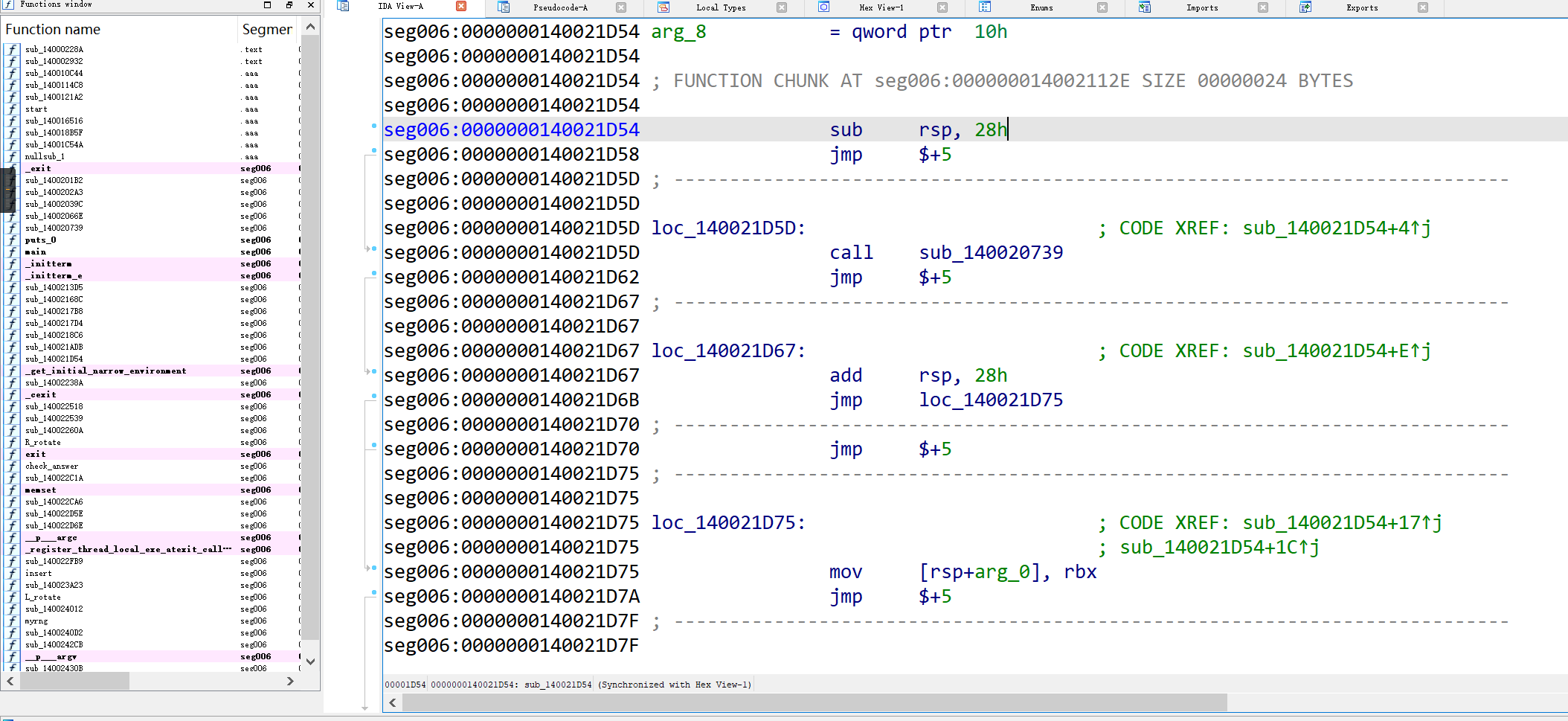
IDA加载, 找到start函数, 发现是一个很短的汇编函数:

进一步发现, 几乎整个代码段都是相似的模式. 根据计算地址后是否直接retn可以将混淆模式分为两种, 第一种模式如下:
... ; 原来的汇编代码
push rax
push rax
pushfq
call $+5
pop rax
add/xor rax, some_imm
mov [rsp+40h+var_30], rax
popfq
pop rax
retn
不难发现, 该段汇编代码的作用就是将call $+5的下一条指令的地址add或者xor上某个立即数, 再通过retn跳转到计算出来的新地址, 因此这种模式可以看作是一种jmp, 其通过将原来的线性汇编代码分割成多个小块, 并且随机打乱了顺序来进行混淆.
第二种模式如下:
push rdx
push rbx
pop rbx
pop rdx
push rax
push rax
pushfq
call $+5
pop rax
add rax, 4A8Ch
mov [rsp+10h], rax
popfq
pop rax
push rax
push rax
pushfq
call $+5
pop rax
add rax, 0FFFFFFFFFFFFCBEFh
mov [rsp+10h], rax
popfq
pop rax
retn
这里可以看作是两次JMP模式的组合. 区别在于, 第一次JMP模式中, 计算完跳转地址后没有立即用retn跳转, 而是又重新开始了新的一次JMP模式. 仔细一想就会发现这个模式等价于做了一次call, 其中第一次放到返回地址里的是call所在的上下文中的下一条指令, 而第二次放进去的是call所调用的函数的地址.
此外还有一些比较简单的无效指令混淆, 目的应该是增加动态调试的难度:
push rax
pop rax
push rbx
pop rbx
push rcx
push rdx
pop rdx
pop rcx
有了以上的分析基础, 就可以着手一步步来去除各种混淆了.
0x01 控制流重建
显然, 阻碍我们分析的最大障碍就是上面提到的两种控制流混淆模式, 因此我们通过脚本先把真正的控制流重建出来. 但在此之前, 需要先对所有指令进行预处理, 主要是处理需要重定位的指令, 记录下他们重定位的目标指令, 以及在他们的目标指令中维护所有指向这个目标地址的指令, 后面的这种”反向链接”是为了在去混淆时将重定位标签顺利地转移出去. 另外, 在这里我们处理重定位的时候, 只需要关心混淆的代码段本身, 因为这部分的目标位置本身就还是有待确定的. 数据段这些部分再patch原exe的时候是不变的, 我们只需计算出其目标的绝对地址, patch时再计算出相对地址就可以了.
还有一点值得注意的是, python没有像C/C++类语言一样的指针可用, 因此如果使用正常的python结构通过反向链接修改重定位标签时会很麻烦, 我这里的思路是把所有指令都放到一个字典里, 用其虚拟地址作为key索引, 相当于人为构造了一个 global mutable singleton, 这样就保证了修改的一致性, 操作起来也比较方便.
from capstone import *
from capstone.x86 import *
class Instruction:
__slots__ = ["va", "s", "mnemonic", "op_str", "bytes", "isvirtual", "relroback",
"relrolabel", "blocklabel", "insn", "extravalist", "realva", "realbytes"]
def __init__(self, insn=None):
if insn:
self.va = insn.address
self.mnemonic = insn.mnemonic
self.op_str = insn.op_str
self.s = insn.mnemonic + " " + insn.op_str
self.bytes = insn.bytes
self.isvirtual = False
self.relroback = []
self.relrolabel = None
self.blocklabel = insn.address
self.insn = insn
self.extravalist = []
self.realva = None
self.realbytes = None
else:
self.va = None
self.mnemonic = None
self.op_str = None
self.s = None
self.bytes = None
self.isvirtual = False
self.relroback = []
self.relrolabel = None
self.blocklabel = None
self.insn = None
self.extravalist = []
self.realva = None
self.realbytes = None
def __str__(self):
return (hex(self.va) if self.va else "none") + "\t" + self.s
# store all addresses that need relocate in instructions' oprands
def prepare_instruction_one(insn):
ins = Instruction(insn)
mnem = insn.mnemonic
# not call $+5
call_pc_ins_bytes = "\xe8\x00\x00\x00\x00"
if insn.bytes != call_pc_ins_bytes:
if "[rip + 0x" in insn.op_str:
# relative addressing
tt = "[rip + 0x"
tmp = insn.op_str[insn.op_str.index(tt) + len(tt):insn.op_str.index("]")]
ins.relrolabel = ins.va + len(ins.bytes) + int(tmp, 16)
elif "[rip - 0x" in insn.op_str:
tt = "[rip - 0x"
tmp = insn.op_str[insn.op_str.index(tt) + len(tt):insn.op_str.index("]")]
ins.relrolabel = ins.va + len(ins.bytes) - int(tmp, 16)
elif (iscjump(mnem) or mnem == "jmp" or (insn.bytes != call_pc_ins_bytes and mnem == "call")) \
and "0x" in insn.op_str: # exclude such "jmp rax"
# j to abslute address
ins.relrolabel = int(insn.op_str, 16)
return ins
if __name__ == "__main__":
# capstone engine initialization
md = Cs(CS_ARCH_X86, CS_MODE_64)
# get all instructions
with open("tttree2.exe", "rb") as f:
all_bytes = f.read()
PATCH_CONTENT = bytearray(len(all_bytes))
raw_binary_1 = all_bytes[0x400:0x25f2] # [0x140001000, 0x1400031F2)
raw_binary_2 = all_bytes[0x4000:0x10695] # [0x140010000, 0x14001C695)
all_insns = list(md.disasm(raw_binary_1, 0x140001000)) + list(md.disasm(raw_binary_2, 0x140010000))
print("labeling all_insns")
all_vas = [insn.address for insn in all_insns]
all_insns = {insn.address: prepare_instruction_one(insn) for insn in all_insns}
然后就是重建控制流, 我们枚举所有的指令, 并按照其模式进行分类:
- 对于
JMP类型的混淆, 我们在当前block加入一条空白的x86jmp指令b”\xE9\x00\x00\x00\x00″, 并且记录他的重定位目标及其反向链接. 之后我们结束当前这个块, 并在当前块和下一个块之间加入一条有向边. - 对于
CALL类型, 我们创建一条空白的call指令和一条空白的jmp指令, 加入到当前的block里, 同时也要处理好两条指令的重定位目标和反向链接. 同样的, 结束当前块, 在当前块和下一个块(注意不是call的块)之间加入一条有向边. - 对于条件跳转和直接跳转指令, 只需结束当前块+加边
- 对于
ret指令, 直接结束当前块, 然后处理下一条指令 - 其他的就是正常的指令了, 一条一条加入当前block即可
def is_jmp_pattern(insts: list[Instruction]):
if is_basic_pattern(insts[0:]) and insts[9].s.startswith("ret"):
return parse_address(insts[4].va, insts[5])
else:
return -1
def is_call_pattern(insts: list[Instruction]):
if is_basic_pattern(insts) \
and not insts[9].s.startswith("ret") \
and is_basic_pattern(insts[9:]) \
and insts[18].s.startswith("ret"): # FIXME maybe other instructions between two?
ra = parse_address(insts[4].va, insts[5])
ja = parse_address(insts[13].va, insts[14])
return (ra, ja)
else:
return (-1, -1)
def add_edge(blocks, u, v):
blocks[u].outedges.append(v)
blocks[v].inedges.append(u)
def build_basic_control_graph(all_vas, all_insns):
blocks = {va: Block() for va, ins in all_insns.items()}
va_ins_map = {va: None for va, ins in all_insns.items()}
# build control flow graph
idx = 0
new_block = True
cur_startva = all_vas[0]
while idx < len(all_vas):
cur_va = all_vas[idx]
ins = all_insns[cur_va]
if ins.relrolabel:
if is_text_seg(ins.relrolabel): # Except data segment..6.
all_insns[ins.relrolabel].relroback.append(cur_va) # reverse connect
va_ins_map[ins.va] = ins
if new_block:
cur_startva = ins.va
new_block = False
ja1, ra, ja2 = -1, -1, -1
if idx + 10 < len(all_vas):
ja1 = is_jmp_pattern([all_insns[vax] for vax in all_vas[idx:idx + 10]])
if idx + 19 < len(all_vas):
ra, ja2 = is_call_pattern([all_insns[vax] for vax in all_vas[idx:idx + 19]])
if ja1 != -1:
# need relrolabel transfer
moveto_va = ja1
for from_va in all_insns[cur_va].relroback:
all_insns[moveto_va].relroback.append(from_va)
all_insns[from_va].relrolabel = moveto_va
# add a JMP instruction
jmp_bytes = b"\xE9\x00\x00\x00\x00"
jmp_ins = Instruction(list(md.disasm(jmp_bytes, ins.va))[0])
jmp_ins.relrolabel = ja1
all_insns[ja1].relroback.append(jmp_ins.va)
all_insns[jmp_ins.va] = jmp_ins # update ins!
blocks[cur_startva].insts.append(jmp_ins.va)
add_edge(blocks, cur_startva, ja1)
new_block = True
idx += 10
elif ja2 != -1:
# add a CALL instruction
call_bytes = b"\xE8\x00\x00\x00\x00"
call_ins = Instruction(list(md.disasm(call_bytes, ins.va))[0])
call_ins.relrolabel = ja2 # FIXME here is absolute address but when reloc should be relative
all_insns[ja2].relroback.append(call_ins.va)
all_insns[call_ins.va] = call_ins # update ins!
blocks[cur_startva].insts.append(call_ins.va)
# add a JMP instruction
jmp_bytes = b"\xE9\x00\x00\x00\x00"
jmp_ins = Instruction(list(md.disasm(jmp_bytes, ins.va + len(call_bytes)))[0]) # add jmp after call
jmp_ins.relrolabel = ra
all_insns[ra].relroback.append(jmp_ins.va)
all_insns[jmp_ins.va] = jmp_ins # update ins!
blocks[cur_startva].insts.append(jmp_ins.va)
add_edge(blocks, cur_startva, ra)
new_block = True
idx += 19
elif ins.mnemonic == "jmp" and ins.relrolabel:
blocks[cur_startva].insts.append(ins.va)
if is_text_seg(ins.relrolabel):
add_edge(blocks, cur_startva, ins.relrolabel)
new_block = True
idx += 1
elif iscjump(ins.mnemonic) and ins.relrolabel:
blocks[cur_startva].insts.append(ins.va)
if is_text_seg(ins.va + len(ins.bytes)):
add_edge(blocks, cur_startva, ins.va + len(ins.bytes)) # near
if is_text_seg(ins.relrolabel):
add_edge(blocks, cur_startva, ins.relrolabel) # far
new_block = True
idx += 1
elif "ret" in ins.s:
blocks[cur_startva].insts.append(ins.va)
new_block = True
idx += 1
else:
# just regular instruction
blocks[cur_startva].insts.append(ins.va)
idx += 1
return blocks, va_ins_map
0x02 无效指令消除
这一部分主要是把一些无用的指令消除(主要是push/pop对), 逻辑相对比较简单, 但是要注意消除的指令的重定位标签要及时更新.
def is_pushpop_pattern(insts: list[Instruction]):
if len(insts) < 2:
return -1
if insts[0].s.startswith("push") \
and insts[1].s.startswith("pop") \
and insts[0].op_str == insts[1].op_str \
or insts[1].s.startswith("push") \
and insts[0].s.startswith("pop") \
and insts[0].op_str == insts[1].op_str:
return 2
if len(insts) < 4:
return -1
sum={}
for i in range(4):
key = insts[i].op_str
if insts[i].s.startswith("push"):
if key in sum:
sum[key] += 1
else:
sum[key] = 1
elif insts[i].s.startswith("pop"):
if key in sum:
sum[key] += -1
else:
sum[key] = -1
else:
return -1
for k,v in sum.items():
if v != 0:
return -1
return 4
def simplify(blocks, all_insns):
for va, block in blocks.items():
tmp_insts = []
idx = 0
while idx < len(block.insts):
cur_va = block.insts[idx]
pp = -1
if idx+4<len(block.insts):
pp = is_pushpop_pattern([all_insns[vax] for vax in block.insts[idx:idx+4]])
if pp == -1 and idx+2<len(block.insts):
pp = is_pushpop_pattern([all_insns[vax] for vax in block.insts[idx:idx+2]])
if pp == -1:
tmp_insts.append(block.insts[idx])
idx +=1
else:
if idx+pp < len(block.insts):
moveto_va = block.insts[idx+pp]
# move linked-label to next instructions
for i in range(pp):
cur_vax = block.insts[idx+i]
for from_va in all_insns[cur_vax].relroback:
all_insns[moveto_va].relroback.append(from_va)
all_insns[from_va].relrolabel = moveto_va
idx += pp
blocks[va].insts = tmp_insts
0x03 线性汇编转换与地址重定位
在这一步, 我们要将控制流图转换为线性排列的汇编字节码, 我这里简单粗暴地用了dfs来排列所有的指令, 并将所有待重定位的代码段地址留空, 数据段地址因为可能出现在多种指令中, 不便统一格式, 因此先按照原样patch, 下一步重定位再特殊处理:
VIS=set()
def place_realbytes_dfs(from_va, blocks, all_insns):
global PC, REAL_INSTS, REAL_ADDRESS_MAP, VIS
if from_va in VIS:
return
else:
VIS.add(from_va)
for vax in blocks[from_va].insts:
ins = all_insns[vax]
mnem = ins.mnemonic
# place holder for relocation
if ins.relrolabel:
if "[rip " in ins.s and not is_text_seg(ins.relrolabel):
ins.realbytes = ins.bytes
elif "[rip " in ins.s:
ins.realbytes = ins.bytes
elif mnem == "call":
ins.realbytes = b"\xe8\x00\x00\x00\x00"
elif mnem == "jmp":
ins.realbytes = b"\xe9\x00\x00\x00\x00"
elif iscjump(mnem):
ins.realbytes = cjumpbytes(mnem) + b"\x00\x00\x00\x00"
else:
raise Exception("relrolabel error1")
else:
ins.realbytes = ins.bytes
REAL_INSTS.append(ins.va)
REAL_ADDRESS_MAP[ins.va] = PC
ins.realva = PC
PC += len(ins.realbytes)
for to_va in blocks[from_va].outedges:
place_realbytes_dfs(to_va, blocks, all_insns)
然后就是各种不同情况下的重定位计算, 主要是将真实的绝对地址转换成相对地址.
def relocation(all_insns):
for vax in REAL_INSTS:
ins = all_insns[vax]
mnem = ins.mnemonic
if ins.relrolabel:
if is_text_seg(ins.relrolabel):
realtarget = REAL_ADDRESS_MAP[ins.relrolabel]
if "[rip " in ins.s:
ins.realbytes = ins.bytes[:-4] + p32(realtarget)
elif mnem == "call":
# recalculate offset of call
ins.realbytes = b"\xE8" + p32(realtarget - ins.realva - 0x5) #b"\xe8\x00\x00\x00\x00"
elif mnem == "jmp":
ins.realbytes = b"\xE9" + p32(realtarget - ins.realva - 0x5) # b"\xe9\x00\x00\x00\x00"
elif iscjump(mnem):
ins.realbytes = cjumpbytes(mnem) + p32(realtarget - ins.realva - len(cjumpbytes(mnem)) - 0x04)
else:
raise Exception("relrolabel error2")
elif "[rip " in ins.s:
# point to original address in .data
ins.realbytes = ins.bytes[:-4] + p32(ins.relrolabel - ins.realva - len(ins.bytes))
然后将所有的字节patch到一个binary文件中, 并输出start现在的真实地址:
def patch_real_bytes():
resultbytes = bytearray()
for vax in REAL_INSTS:
ins = all_insns[vax]
resultbytes.extend(ins.realbytes)
return resultbytes
print("patch real bytes")
resultbytes = patch_real_bytes()
print("write to .bin")
with open("tttree2_patched.bin", "wb") as f:
f.write(resultbytes)
print(f"start at {hex(REAL_ADDRESS_MAP[0x1400133BB])}")
0x04 最终结果
最终我们把处理好的binary patch到原exe的0x140020000地址处, 跳转到start现在的地址(0x140021d54)处, 按C转换成代码, 再按P制造一个函数, 就可以看到IDA自动识别出来了大量的函数和交叉引用:
此时F5的结果就已经很好看了, 在start中很容易找到main函数:
int __cdecl main(int argc, const char **argv, const char **envp)
{
unsigned int v3; // ecx
int i; // [rsp+20h] [rbp-1B8h]
int j; // [rsp+24h] [rbp-1B4h]
__int64 v7; // [rsp+28h] [rbp-1B0h]
int v8[102]; // [rsp+40h] [rbp-198h]
v3 = sub_140021ADB(0i64);
srand(v3);
puts_0("flag:");
sub_140022FB9("%s", input_flag);
for ( i = 0; i < 32; ++i )
v8[i] = i + input_flag[i + 7] + (int)myrng() % 107 + 97;
if ( input_flag[0] != 'S'
&& input_flag[1] != 'U'
&& input_flag[2] != 'S'
&& input_flag[3] != 'C'
&& input_flag[4] != 'T'
&& input_flag[5] != 'F'
&& input_flag[6] != '{'
&& input_flag[39] != '}' )
{
puts_0("error");
exit(0);
}
v7 = -1i64;
do
++v7;
while ( input_flag[v7] );
if ( v7 != 40 )
{
puts_0("error");
exit(0);
}
for ( j = 0; j < 32; ++j )
insert((int *)&pos, v8[j]);
check_answer((int *)&pos);
puts_0("\nYES\n");
return 0;
}
进到insert这个函数里, 简单地修复一下结构体, 就可以看出来treap树的逻辑了:
__int64 __fastcall insert(int *pos, int x)
{
__int64 result; // rax
if ( *pos )
{
++tree[*pos].size;
if ( tree[*pos].val == x )
{
result = (unsigned int)(tree[*pos].count + 1);// ++count
tree[*pos].count = result;
}
else if ( x > tree[*pos].val )
{
insert(&tree[*pos].right, x); // right
result = 28i64 * tree[*pos].right;
if ( *(int *)((char *)&tree[0].pri + result) < tree[*pos].pri )
result = (__int64)L_rotate(pos);
}
else
{
insert(&tree[*pos].left, x); // left
result = 28i64 * tree[*pos].left;
if ( *(int *)((char *)&tree[0].pri + result) < tree[*pos].pri )
result = (__int64)R_rotate(pos);
}
}
else
{
*pos = ++tot;
tree[*pos].count = 1;
tree[*pos].size = 1;
tree[*pos].val = x; // value
tree[*pos].C = input_flag[*pos + 6]; // char
dword_140007220[rncnt] = myrng();
tree[*pos].pri = dword_140007220[rncnt];
result = (unsigned int)++rncnt;
}
return result;
}
然后是check_answer函数:
int *__fastcall check_answer(int *root)
{
int *result; // rax
unsigned int v2; // [rsp+8h] [rbp-10h]
int v3; // [rsp+Ch] [rbp-Ch]
result = root;
if ( *root )
{
check_answer(&tree[*root].left);
check_answer(&tree[*root].right);
if ( tree[*root].left && qword_1400060C0[dword_1400073BC] != tree[*root].C + 23 * tree[*root].left )
{
puts("error");
exit(0);
}
if ( tree[*root].right && qword_1400061C0[dword_1400073BC] != tree[*root].C + 23 * tree[*root].right )
{
puts("error");
exit(0);
}
v3 = tree[*root].val;
v2 = dword_140006040[dword_1400073BC++];
result = (int *)v2;
if ( v3 != v2 )
{
puts("error");
exit(0);
}
}
return result;
}
后面的分析相对就简单很多了, 就是一个后序+中序恢复输入的过程, 其他很多WP都有讲, 不再赘述.
0x05 后记
比赛期间在flutter那题 (最后全场1解) 卡了很久很久, 头昏脑胀之后来看了这个tttree2.exe, 一眼看感觉混淆模式挺简单的, 就直接开始动手写脚本. 事实证明, 没有想清楚就直接写代码是非常错误的决定, 在写了200+行反复调试的IDAPython之后仍然没有很好的处理完所有的混淆(主要是各种重定位). 当然挂调试器一点一点扣逻辑也并不是不可以, 但对本人来说不太能接受这样的时间/精力成本, 另外私以为这种暴力硬怼的做法并不符合逆向工程的哲学. 因此, 没有在比赛当场成功写出来去混淆的脚本对本人来说就已经是失败了.
赛后学习了其他队伍师傅的wp, 才意识到自己并没有分辨出来第二种混淆模式(也就是call的混淆), 这样的话处理一定是错误的. 但除此之外, 目前看到的大部分wp(包括官方wp)其实都并没有很好的达到去混淆, 最后得到的代码还是有一些残缺不全, 只不过足以推断出程序逻辑罢了, 只有0ops一位师傅的脚本基本上完全还原了原程序, 不过去混淆的python脚本达到了700+行, 对于一个ctf题目来说已经很多了. 这个脚本由于是队内wp就不放出来了, 在此隔空膜拜一下hzqmwne师傅, orzorz.
实际上, 这份wp并没有完全让我搞懂hzqmwne师傅去混淆的思路(代码阅读理解太菜了), 更多的是在基本的数据结构上给了我启发. 对于这种控制流重建的去混淆, 其实本质就是一个图论算法问题, 而众所周知图论题没有设计好数据结构的话写起来是非常难受的. 自己此前只在ACM里用C/C++语言写过图相关的数据结构与算法, 而Python中缺乏了指针等一些自己惯用的操作, 导致构建图的时候完全没有考虑清楚, 这也是当时没有做出来本题的另一个原因.
感觉自己在二进制程序分析这方面还是有很大提高的空间, 还需要多多学习.
References
Appendix
完整代码:
from typing import List, Dict
from capstone import *
from capstone.x86 import *
def p32(n):
n &= 0xffffffff
return n.to_bytes(4, "little")
def u32(s):
assert len(s) == 4
return int.from_bytes(s, "little")
# is conditional jump
def iscjump(mnemonic):
if mnemonic.startswith("j") and mnemonic != "jmp":
assert mnemonic in ["jno", "jo", "jnc", "jnb", "jae", "jc", "jb", "jnae",
"jnz", "jne", "jz", "je", "jnbe", "ja", "jbe", "jna",
"jns", "js", "jnp", "jpo", "jp", "jpe", "jnl", "jge",
"jl", "jnge", "jnle", "jg", "jle", "jng"], mnemonic
return True
return False
def cjumpbytes(mnem):
m = {
"jo": b"\x0f\x80",
"jno": b"\x0f\x81",
"jb": b"\x0f\x82",
"jae": b"\x0f\x83",
"je": b"\x0f\x84",
"jne": b"\x0f\x85",
"jbe": b"\x0f\x86",
"ja": b"\x0f\x87",
"js": b"\x0f\x88",
"jns": b"\x0f\x89",
"jp": b"\x0f\x8a",
"jnp": b"\x0f\x8b",
"jl": b"\x0f\x8c",
"jge": b"\x0f\x8d",
"jle": b"\x0f\x8e",
"jg": b"\x0f\x8f",
}
return m[mnem]
def is_text_seg(addr):
return (0x140001000 <= addr < 0x140003200) or (0x0140010000 <= addr < 0x14001C695)
class Instruction:
__slots__ = ["va", "s", "mnemonic", "op_str", "bytes", "isvirtual", "relroback",
"relrolabel", "blocklabel", "insn", "extravalist", "realva", "realbytes"]
def __init__(self, insn=None):
if insn:
self.va = insn.address
self.mnemonic = insn.mnemonic
self.op_str = insn.op_str
self.s = insn.mnemonic + " " + insn.op_str
self.bytes = insn.bytes
self.isvirtual = False
self.relroback = []
self.relrolabel = None
self.blocklabel = insn.address
self.insn = insn
self.extravalist = []
self.realva = None
self.realbytes = None
else:
self.va = None
self.mnemonic = None
self.op_str = None
self.s = None
self.bytes = None
self.isvirtual = False
self.relroback = []
self.relrolabel = None
self.blocklabel = None
self.insn = None
self.extravalist = []
self.realva = None
self.realbytes = None
def __str__(self):
return (hex(self.va) if self.va else "none") + "\t" + self.s
class Block:
__slots__ = ["label", "startva", "insts", "inedges", "outedges"]
def __init__(self):
self.label = None
# self.startva = None
# self.jmpva = None
self.insts = []
self.inedges = []
self.outedges = []
# "loc_" + hex(self.startva).lstrip("0x").upper() + ":"
# f"loc_{self.startva:X}:\n"
def __str__(self):
r = ""
r += f"; {hex(self.label)}, {len(self.inedges)} {[hex(c) for c in self.inedges]} {len(self.outedges)} {[hex(c) for c in self.outedges]}:\n"
for inst in self.insts:
r += str(inst) + "\n"
return r
def useless(self) -> bool:
if len(self.insts) != 0 or len(self.inedges) != 0 or (self.outedges) != 0:
return True
return False
REAL_ADDRESS_MAP = {}
REAL_INSTS = []
PC = 0x140020000
# store all addresses that need relocate in instructions' oprands
def prepare_instruction_one(insn):
ins = Instruction(insn)
mnem = insn.mnemonic
# not call $+5
call_pc_ins_bytes = "\xe8\x00\x00\x00\x00"
if insn.bytes != call_pc_ins_bytes:
if "[rip + 0x" in insn.op_str:
# relative addressing
tt = "[rip + 0x"
tmp = insn.op_str[insn.op_str.index(tt) + len(tt):insn.op_str.index("]")]
ins.relrolabel = ins.va + len(ins.bytes) + int(tmp, 16)
elif "[rip - 0x" in insn.op_str:
tt = "[rip - 0x"
tmp = insn.op_str[insn.op_str.index(tt) + len(tt):insn.op_str.index("]")]
ins.relrolabel = ins.va + len(ins.bytes) - int(tmp, 16)
elif (iscjump(mnem) or mnem == "jmp" or (insn.bytes != call_pc_ins_bytes and mnem == "call")) \
and "0x" in insn.op_str: # exclude such "jmp rax"
# j to abslute address
ins.relrolabel = int(insn.op_str, 16)
return ins
def parse_address(va, ins):
ra_base = va
ra_offset = int(ins.op_str.split()[1], 16)
ra = 0
if ins.s.startswith("xor rax,"):
ra = (ra_base ^ ra_offset) & ((1 << 64) - 1)
elif ins.s.startswith("add rax,"):
ra = (ra_base + ra_offset) & ((1 << 64) - 1)
else:
raise Exception("Not ADD or XOR????")
return ra
def is_basic_pattern(insts: list[Instruction]):
if insts[0].s.startswith("push rax") \
and insts[1].s.startswith("push rax") \
and insts[2].s.startswith("pushf") \
and insts[3].s.startswith("call") \
and insts[4].s.startswith("pop rax") \
and (insts[5].s.startswith("xor rax,") or insts[5].s.startswith("add rax,")) \
and insts[6].s.startswith("mov qword ptr [rsp + 0x10], rax") \
and insts[7].s.startswith("popf") \
and insts[8].s.startswith("pop rax"):
return True
return False
def is_jmp_pattern(insts: list[Instruction]):
if is_basic_pattern(insts[0:]) and insts[9].s.startswith("ret"):
return parse_address(insts[4].va, insts[5])
else:
return -1
def is_call_pattern(insts: list[Instruction]):
if is_basic_pattern(insts) \
and not insts[9].s.startswith("ret") \
and is_basic_pattern(insts[9:]) \
and insts[18].s.startswith("ret"): # FIXME maybe other instructions between two?
ra = parse_address(insts[4].va, insts[5])
ja = parse_address(insts[13].va, insts[14])
return (ra, ja)
else:
return (-1, -1)
def add_edge(blocks, u, v):
blocks[u].outedges.append(v)
blocks[v].inedges.append(u)
def build_basic_control_graph(all_vas, all_insns):
blocks = {va: Block() for va, ins in all_insns.items()}
va_ins_map = {va: None for va, ins in all_insns.items()}
# build control flow graph
idx = 0
new_block = True
cur_startva = all_vas[0]
while idx < len(all_vas):
cur_va = all_vas[idx]
ins = all_insns[cur_va]
if ins.relrolabel:
if is_text_seg(ins.relrolabel): # Except data segment..6.
all_insns[ins.relrolabel].relroback.append(cur_va) # reverse connect
va_ins_map[ins.va] = ins
if new_block:
cur_startva = ins.va
new_block = False
ja1, ra, ja2 = -1, -1, -1
if idx + 10 < len(all_vas):
ja1 = is_jmp_pattern([all_insns[vax] for vax in all_vas[idx:idx + 10]])
if idx + 19 < len(all_vas):
ra, ja2 = is_call_pattern([all_insns[vax] for vax in all_vas[idx:idx + 19]])
if ja1 != -1:
# need relrolabel transfer
moveto_va = ja1
for from_va in all_insns[cur_va].relroback:
all_insns[moveto_va].relroback.append(from_va)
all_insns[from_va].relrolabel = moveto_va
# move graph connections to next block
# for from_va in blocks[cur_va].inedges:
# indices_to_replace = [i for i, x in enumerate(blocks[from_va].outedges) if x == cur_va]
# blocks[from_va].outedges[indices_to_replace[0]] = moveto_va
# blocks[moveto_va].inedges.append(from_va)
# add a JMP instruction
jmp_bytes = b"\xE9\x00\x00\x00\x00"
jmp_ins = Instruction(list(md.disasm(jmp_bytes, ins.va))[0])
jmp_ins.relrolabel = ja1
all_insns[ja1].relroback.append(jmp_ins.va)
all_insns[jmp_ins.va] = jmp_ins # update ins!
blocks[cur_startva].insts.append(jmp_ins.va)
add_edge(blocks, cur_startva, ja1)
new_block = True
idx += 10
elif ja2 != -1:
# add a CALL instruction
call_bytes = b"\xE8\x00\x00\x00\x00"
call_ins = Instruction(list(md.disasm(call_bytes, ins.va))[0])
call_ins.relrolabel = ja2 # FIXME here is absolute address but when reloc should be relative
all_insns[ja2].relroback.append(call_ins.va)
all_insns[call_ins.va] = call_ins # update ins!
blocks[cur_startva].insts.append(call_ins.va)
# add a JMP instruction
jmp_bytes = b"\xE9\x00\x00\x00\x00"
jmp_ins = Instruction(list(md.disasm(jmp_bytes, ins.va + len(call_bytes)))[0]) # add jmp after call
jmp_ins.relrolabel = ra
all_insns[ra].relroback.append(jmp_ins.va)
all_insns[jmp_ins.va] = jmp_ins # update ins!
blocks[cur_startva].insts.append(jmp_ins.va)
add_edge(blocks, cur_startva, ra)
new_block = True
idx += 19
elif ins.mnemonic == "jmp" and ins.relrolabel:
blocks[cur_startva].insts.append(ins.va)
if is_text_seg(ins.relrolabel):
add_edge(blocks, cur_startva, ins.relrolabel)
new_block = True
idx += 1
elif iscjump(ins.mnemonic) and ins.relrolabel:
blocks[cur_startva].insts.append(ins.va)
if is_text_seg(ins.va + len(ins.bytes)):
add_edge(blocks, cur_startva, ins.va + len(ins.bytes)) # near
if is_text_seg(ins.relrolabel):
add_edge(blocks, cur_startva, ins.relrolabel) # far
new_block = True
idx += 1
elif "ret" in ins.s:
blocks[cur_startva].insts.append(ins.va)
new_block = True
idx += 1
else:
# just regular instruction
blocks[cur_startva].insts.append(ins.va)
idx += 1
return blocks, va_ins_map
def is_pushpop_pattern(insts: list[Instruction]):
if len(insts) < 2:
return -1
if insts[0].s.startswith("push") \
and insts[1].s.startswith("pop") \
and insts[0].op_str == insts[1].op_str \
or insts[1].s.startswith("push") \
and insts[0].s.startswith("pop") \
and insts[0].op_str == insts[1].op_str:
return 2
if len(insts) < 4:
return -1
sum = {}
for i in range(4):
key = insts[i].op_str
if insts[i].s.startswith("push"):
if key in sum:
sum[key] += 1
else:
sum[key] = 1
elif insts[i].s.startswith("pop"):
if key in sum:
sum[key] += -1
else:
sum[key] = -1
else:
return -1
for k, v in sum.items():
if v != 0:
return -1
return 4
def simplify(blocks, all_insns):
for va, block in blocks.items():
tmp_insts = []
idx = 0
while idx < len(block.insts):
cur_va = block.insts[idx]
pp = -1
if idx + 4 < len(block.insts):
pp = is_pushpop_pattern([all_insns[vax] for vax in block.insts[idx:idx + 4]])
if pp == -1 and idx + 2 < len(block.insts):
pp = is_pushpop_pattern([all_insns[vax] for vax in block.insts[idx:idx + 2]])
if pp == -1:
tmp_insts.append(block.insts[idx])
idx += 1
else:
if idx + pp < len(block.insts):
moveto_va = block.insts[idx + pp]
# move linked-label to next instructions
for i in range(pp):
cur_vax = block.insts[idx + i]
for from_va in all_insns[cur_vax].relroback:
all_insns[moveto_va].relroback.append(from_va)
all_insns[from_va].relrolabel = moveto_va
# move graph connections to next block
# for from_va in blocks[cur_va].inedges:
# indices_to_replace = [i for i, x in enumerate(blocks[from_va].outedges) if x == cur_va]
# blocks[from_va].outedges[indices_to_replace[0]] = moveto_va
# blocks[moveto_va].inedges.append(from_va)
idx += pp
blocks[va].insts = tmp_insts
VIS = set()
def place_realbytes_dfs(from_va, blocks, all_insns):
global PC, REAL_INSTS, REAL_ADDRESS_MAP, VIS
if from_va in VIS:
return
else:
VIS.add(from_va)
for vax in blocks[from_va].insts:
ins = all_insns[vax]
mnem = ins.mnemonic
# place holder for relocation
if ins.relrolabel:
if "[rip " in ins.s and not is_text_seg(ins.relrolabel):
ins.realbytes = ins.bytes # FIXME data segment not considered
elif "[rip " in ins.s:
ins.realbytes = ins.bytes
elif mnem == "call":
ins.realbytes = b"\xe8\x00\x00\x00\x00"
elif mnem == "jmp":
ins.realbytes = b"\xe9\x00\x00\x00\x00"
elif iscjump(mnem):
ins.realbytes = cjumpbytes(mnem) + b"\x00\x00\x00\x00"
else:
print(ins.s)
print(hex(ins.va))
print(hex(ins.relrolabel))
print(is_text_seg(ins.relrolabel))
raise Exception("relrolabel error1")
else:
ins.realbytes = ins.bytes
REAL_INSTS.append(ins.va)
REAL_ADDRESS_MAP[ins.va] = PC
ins.realva = PC
PC += len(ins.realbytes)
for to_va in blocks[from_va].outedges:
place_realbytes_dfs(to_va, blocks, all_insns)
def relocation(all_insns):
for vax in REAL_INSTS:
ins = all_insns[vax]
mnem = ins.mnemonic
if ins.relrolabel:
if is_text_seg(ins.relrolabel):
realtarget = REAL_ADDRESS_MAP[ins.relrolabel]
if "[rip " in ins.s:
ins.realbytes = ins.bytes[:-4] + p32(realtarget)
elif mnem == "call":
# recalculate offset of call
ins.realbytes = b"\xE8" + p32(realtarget - ins.realva - 0x5) # b"\xe8\x00\x00\x00\x00"
elif mnem == "jmp":
ins.realbytes = b"\xE9" + p32(realtarget - ins.realva - 0x5) # b"\xe9\x00\x00\x00\x00"
elif iscjump(mnem):
ins.realbytes = cjumpbytes(mnem) + p32(realtarget - ins.realva - len(cjumpbytes(mnem)) - 0x04)
else:
raise Exception("relrolabel error2")
elif "[rip " in ins.s:
# point to original address in .data
ins.realbytes = ins.bytes[:-4] + p32(ins.relrolabel - ins.realva - len(ins.bytes))
def patch_real_bytes():
resultbytes = bytearray()
for vax in REAL_INSTS:
ins = all_insns[vax]
resultbytes.extend(ins.realbytes)
return resultbytes
if __name__ == "__main__":
# capstone engine initialization
md = Cs(CS_ARCH_X86, CS_MODE_64)
# get all instructions
with open("tttree2.exe", "rb") as f:
all_bytes = f.read()
PATCH_CONTENT = bytearray(len(all_bytes))
raw_binary_1 = all_bytes[0x400:0x25f2] # [0x140001000, 0x1400031F2)
raw_binary_2 = all_bytes[0x4000:0x10695] # [0x140010000, 0x14001C695)
all_insns = list(md.disasm(raw_binary_1, 0x140001000)) + list(md.disasm(raw_binary_2, 0x140010000))
print("labeling all_insns")
all_vas = [insn.address for insn in all_insns]
all_insns = {insn.address: prepare_instruction_one(insn) for insn in all_insns}
print("build control flow graph")
all_blocks, va_ins_map = build_basic_control_graph(all_vas, all_insns)
print(f"Total blocks: {len(all_blocks)}")
print("remove push xxx pop xxx pairs")
simplify(all_blocks, all_insns)
print("generate patch bytes from CFG")
for vax, block in all_blocks.items():
if len(block.inedges) == 0:
place_realbytes_dfs(vax, all_blocks, all_insns)
print("relocation")
relocation(all_insns)
print("patch real bytes")
resultbytes = patch_real_bytes()
print("write to .bin")
with open("tttree2_patched.bin", "wb") as f:
f.write(resultbytes)
print(f"start at {hex(REAL_ADDRESS_MAP[0x1400133BB])}")